

There are many different ways to control costs when implementing modern data pipelines. Here are some ideas to get started.



This article is sponsored and originally appeared on Ascend.io.

The costs of developing and running data pipelines are coming under increasing scrutiny because the bills for infrastructure and data engineering talent are piling up. For data teams, it is time to ask: “How can we have an impact on these runaway costs and still deliver unprecedented business value?” The answer lies in data pipeline optimization.
Like fine-tuning a sports car’s engine, we can boost performance, save resources, and speed up insights in the race for data-driven success. Optimized data pipelines help you cross the finish line faster, using less fuel.
Fortunately, with Ascend, data pipeline optimization doesn’t require esoteric skills or writing lots of custom code. The platform includes a high-performance toolkit with which you can unlock greater value from your chosen infrastructure. Ready to shift gears and speed up your data journey?
Some users fall into an analysis/paralysis trap. They try to anticipate the behavior of their intelligent pipelines during the design stage — often taking weeks before they start building any of them — and second-guess how they will perform. This approach made sense with legacy pipelines, which are brittle the moment you deploy them and can’t be touched because of the long interruptions.
As a result, we recommend a rapid iteration approach: get your pipelines up and delivering business value, then diagnose where tuning to reduce costs makes sense.
To understand how Ascend automation is a game-changer in this area, making intervention and tuning a breeze, we recommend you read this article on intelligent data pipelines.
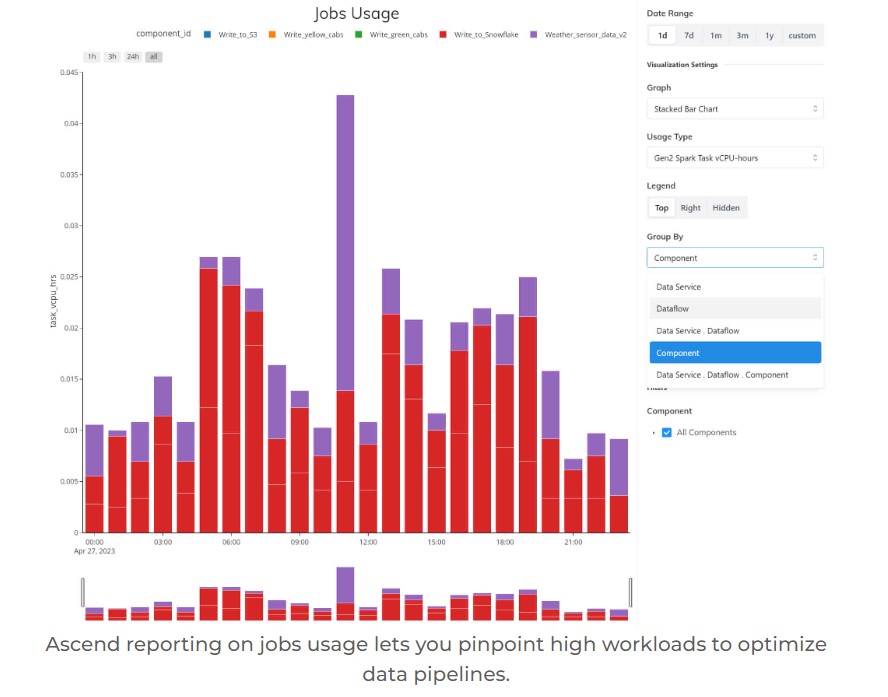
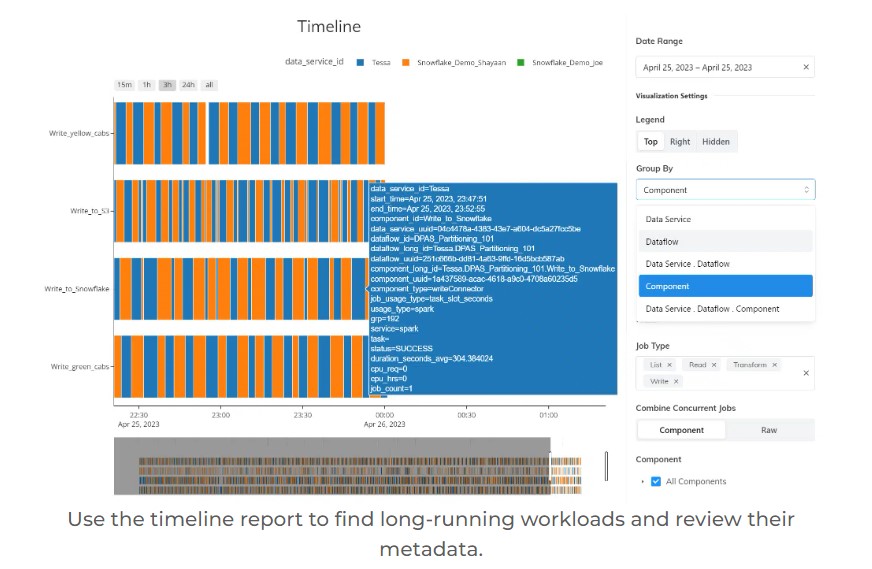
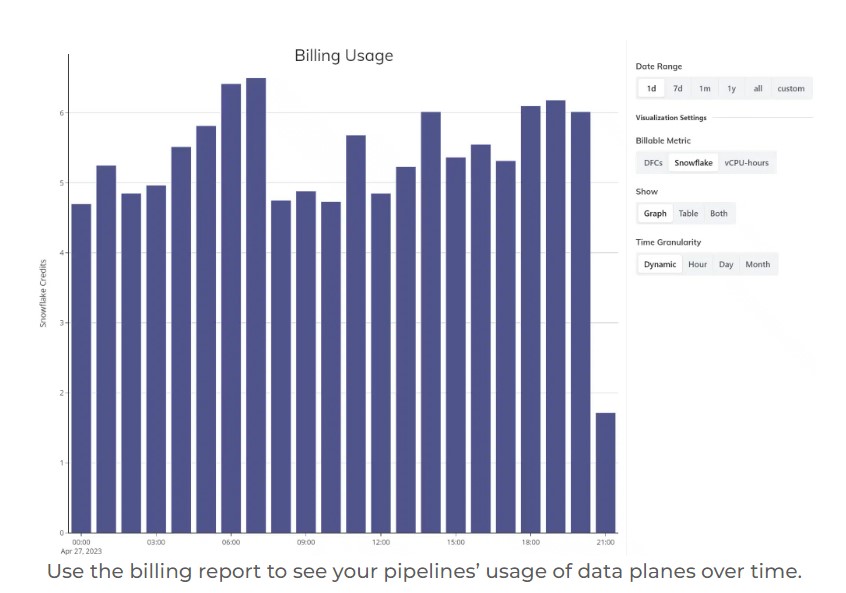
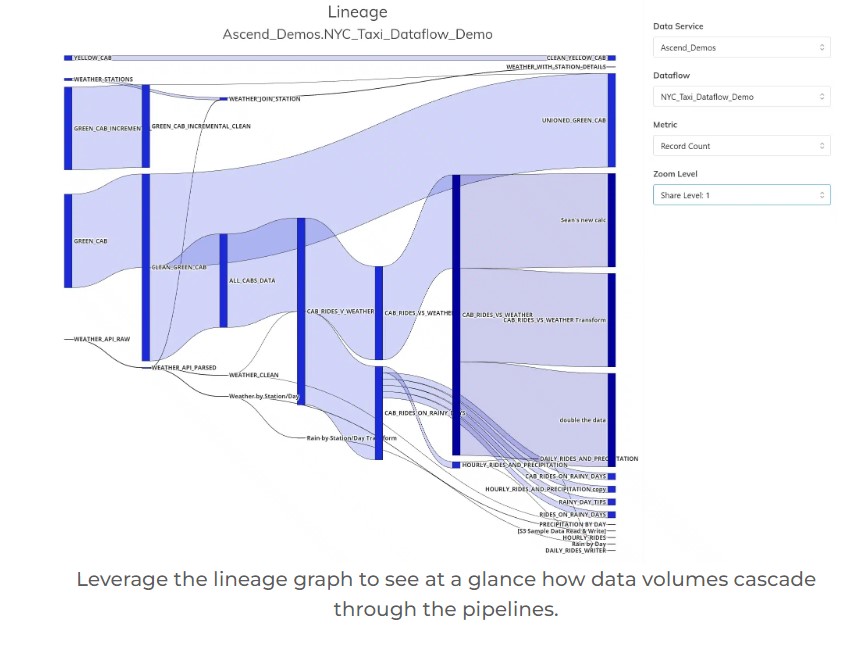
A uniquely useful tool in the platform is the collection of usage reports. These reports include detailed Ascend compute usage data, data plane compute usage data, and lineage visualizations. They pinpoint exactly when and where compute resources are being used, and which part of the data pipelines use the most resources. Armed with these diagnostics, a variety of capabilities let you target and mitigate the hotspots you find. In our March 20 update we described improvements in this area, including a new sunburst visualization.
See example screenshots of these reports below.
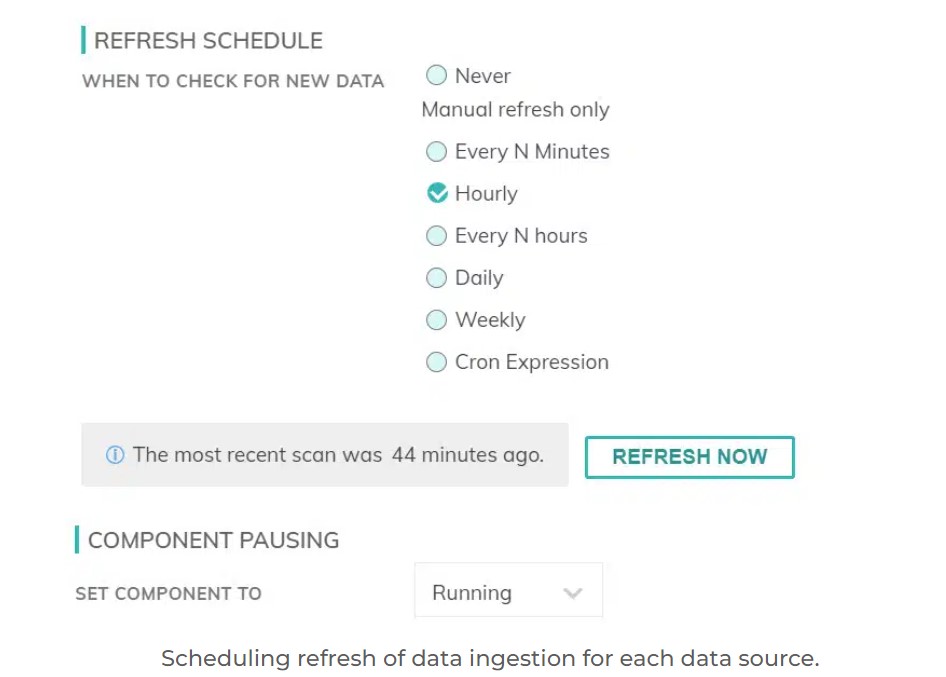
Most source systems for your data have an inherent update cycle. Some produce change log data for every new record, others produce file drops into a cloud bucket every 15 minutes, and others run batch exports nightly. On the other hand, the downstream consumers of your data products have their own timing requirements.
By adjusting the specific periodicity of when data is ingested from each of your data sources, you can control how frequently your intelligent pipelines run. Combined with a thoughtful partitioning approach, this allows you to manage how large the workloads will be while still meeting your downstream users’ timing requirements.
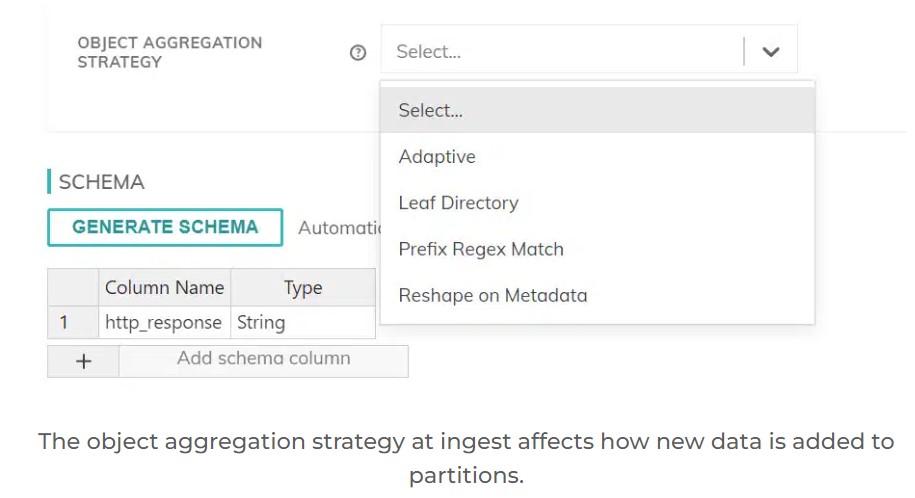
Data partitioning is one of the more powerful levers to tune your intelligent data pipelines. By choosing the right strategies in the right places in the pipelines, you can tune the Ascend platform to:
Ascend will automatically default to the cheapest partitioning option at any step of the pipeline, but an engineer can change this in order to set up partitions that will reduce costs downstream. For example, by selecting the aggregation strategy at any of the ingestion steps, you control how new records are integrated into existing partitions. Similarly, you can choose a (re-)partitioning strategy at any transform.
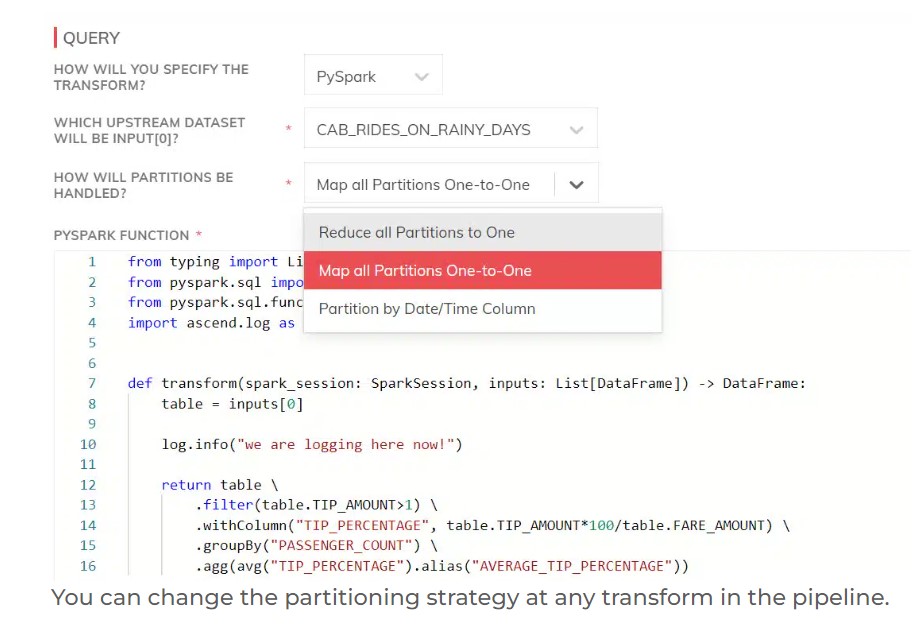
Snowflake, BigQuery, and even Databricks and Spark inherently contain powerful query optimizers that seek to reduce the costs of any single SQL-based transform operation. However, users of PySpark and Databricks Python have far greater control over their data-frames and how they instruct these engines to process data.
Since engineers can distribute transformations in intelligent data pipelines across multiple data planes, the sequence and structure of the transformation steps can significantly impact data pipeline optimization and performance. The flexibility and ease of measuring and intervening in pipelines on Ascend make these areas fertile ground for refactoring and tuning with minimal interruption. Check out the technical sessions of this month’s Data Pipeline Automation Summit for relevant deep dives.
Each data plane (BigQuery, Databricks, and Snowflake) has its distinct cost and performance profiles for different types of workloads. Intelligent data pipelines close the seams between these systems and enable end-to-end pipelines to span the different strengths without losing lineage, continuity, observability, and all the other benefits of data pipeline automation. You can consider each data plane on its own merits for each part of their pipeline network, and stitch them together on Ascend with a few mouse clicks. You can even do A/B testing and mix and match based on empirical cost data!
Less obvious excess costs are incurred in staging data for ingestion at one end and delivery at the other of legacy data pipelines. Intelligent data pipelines make this superfluous:
Additional Reading and Resources

Michael Leppitsch is Head of Data Strategies and Alliances at Ascend.io.
Cloud Data Insights is a blog that provides insights into the latest trends and developments in the cloud data space. We cover topics related to cloud data management, data analytics, data engineering, and data science.
Property of TechnologyAdvice. © 2026 TechnologyAdvice. All Rights Reserved
Advertiser Disclosure: Some of the products that appear on this site are from companies from which TechnologyAdvice receives compensation. This compensation may impact how and where products appear on this site including, for example, the order in which they appear. TechnologyAdvice does not include all companies or all types of products available in the marketplace.













