

Automated ETL paves the way for more accurate insights, informed decision-making, and a nimble response to the fluid nature of data sources and structures.



This article is sponsored and originally appeared on Ascend.io.

In the world of data engineering, the ETL (Extract, Transform, Load) approach has been the cornerstone for managing and processing data. However, the traditional methods of executing ETL are increasingly struggling to meet the escalating demands of today’s data-intensive environments.
This growing disconnect between the scale of data and the capability of traditional ETL methods has brought forth the emergence of automated ETL pipelines: automation to supercharge the ETL processes.
In this article, we’ll delve into what is an automated ETL pipeline, explore its advantages over traditional ETL, and discuss the inherent benefits and characteristics that make it indispensable in the data engineering toolkit.
An automated ETL pipeline is a data integration framework that leverages automation technology to streamline the extraction, transformation, and loading of data. It is designed to minimize manual intervention by automating rote tasks, employing predefined configurations and utilizing machine-led processes to manage vast data flows across different sources and destinations.

A common misconception lies in the notion that automation signals the obsolescence of the human touch in ETL processes. In truth, automated ETL pipelines are not crafted to sideline engineers. Instead, they serve as amplifiers of human capability. By taking over mundane and repetitive chores (sometimes referred to as “custodial engineering”), they free up data engineers to channel their expertise towards more complex, strategic challenges — challenges that require critical thinking, creativity, and domain knowledge.
This not only leads to a more efficient data process but also ensures that the depth and breadth of human intelligence is directed where it truly matters. In this synergy of machine efficiency and human intellect, automated ETL pipelines position themselves as allies, not replacements.
Before unraveling the nuances that set traditional and automated ETL apart, it’s paramount to ground ourselves in the basics of the traditional ETL process. ETL stands for:
For those keen on a deeper exploration of the traditional ETL paradigm, our guide What is ETL? – (Extract, Transform, Load) provides an in-depth perspective.
The differences between traditional and automated ETL lie largely in their approach to handling data. The former, rooted in its classical approach, leans heavily on manual scripts and an ensemble of tools. It demands the tactile touch of humans at nearly every turn — be it in script creation, intricate scheduling for ETL pipelines, or diving deep into manual impact analysis when anomalies arise. This hands-on method can stretch time and is prone to human errors, particularly when grappling with colossal data volumes.
On the flip side, automated ETL pipelines shift the paradigm from manual oversight to intelligent automation. Engineers, rather than being bogged down by routine maintenance, are freed to focus on strategic elements. Equipped with built-in connectors, robust error-handling mechanisms, and capabilities to process data in near real-time, automated ETL pipelines not only enhance the speed of data integration but also ensure a higher degree of accuracy and reliability. The result? A more agile, responsive, and error-resistant data management process.
It’s essential to clarify a prevailing misconception: the Modern Data Stack is not automated ETL. While tools like Fivetran might automate the extraction phase, and dbt facilitates transformation, with platforms like Hightouch streamlining the loading, these tools, in isolation, don’t create an automated ETL process.
The endeavor to stitch together and harmonize these disparate platforms takes substantial time and effort, greatly limiting the amount of automation that can be deployed and putting any automation out of the reach of the majority of small to mid-sized teams. Beyond the initial setup, engineers face the ongoing challenges of adapting to evolving APIs, managing unique data scenarios, and troubleshooting connection discrepancies. How can one achieve seamless automation across point solutions with different operational models?
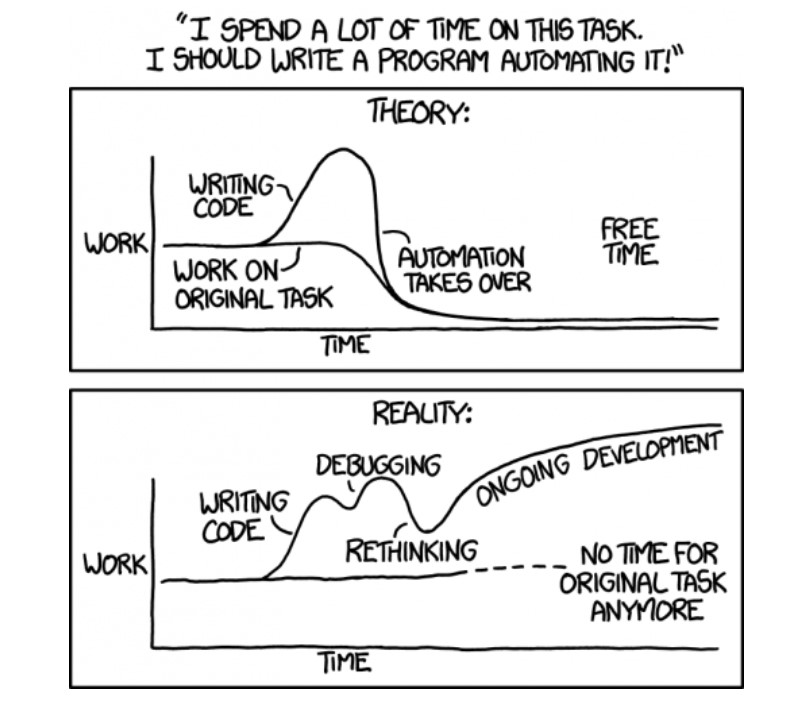
Automation will reduce toil, but not if your engineering team is building the system. Patching together the modern data stack is equivalent to building such a system (source: xkcd.com/1319/).
Automated ETL pipelines address the contemporary challenges faced by data teams. Let’s delve into their defining features:
These characteristics not only differentiate automated ETL pipelines from their traditional counterparts but also underscore their suitability for modern data-intensive environments. As we delve deeper, the ensuing advantages of these features will become even more evident.
The adoption of automation in ETL isn’t just a trend — it’s a strategic shift backed by tangible benefits. While the characteristics of automated ETL pipelines hint at their potential, it’s the realized advantages that truly demonstrate their value in a data-driven environment. Here’s a breakdown of the predominant benefits organizations can reap from implementing automated ETL pipelines:
In essence, the benefits of automated ETL pipelines go beyond mere efficiency. They encompass a holistic improvement in how data is managed, processed, and utilized, making them an invaluable asset for organizations aiming to maximize their data potential.
See also: Five Data Pipeline Best Practices to Follow
The transformational journey from traditional to automated ETL pipelines is a testament to the ever-evolving landscape of data engineering. As data continues to grow in volume and complexity, the tools and methodologies we employ must also evolve.
In embracing automated ETL, organizations are not just opting for efficiency; they’re paving the way for more accurate insights, informed decision-making, and a nimble response to the fluid nature of data sources and structures. As we’ve explored in this article, the shift to automation in ETL isn’t just a mere technological upgrade — it’s a strategic imperative for any enterprise seeking to harness the true potential of its data.
Paul Lacey is Head of Product Marketing at Ascend.io.
Cloud Data Insights is a blog that provides insights into the latest trends and developments in the cloud data space. We cover topics related to cloud data management, data analytics, data engineering, and data science.
Property of TechnologyAdvice. © 2026 TechnologyAdvice. All Rights Reserved
Advertiser Disclosure: Some of the products that appear on this site are from companies from which TechnologyAdvice receives compensation. This compensation may impact how and where products appear on this site including, for example, the order in which they appear. TechnologyAdvice does not include all companies or all types of products available in the marketplace.













