



Deploying open-source Apache Kafka in production offers tremendous capabilities for powerful data streaming at scale. But the road to blissful production deployment often comes with a few surprises along the way. To maintain the performance, reliability, and data durability of your production Kafka cluster, it’s crucial to monitor, prepare for, and react to these seven potential conditions:
1) Unbalanced partition assignment
This is a particularly critical component of maintaining a healthy Kafka cluster. When designing your cluster, balance the number of topics and partitions with the number of consumers and consumer groups that will consume the messages—as well as with the producers that write to these topics.
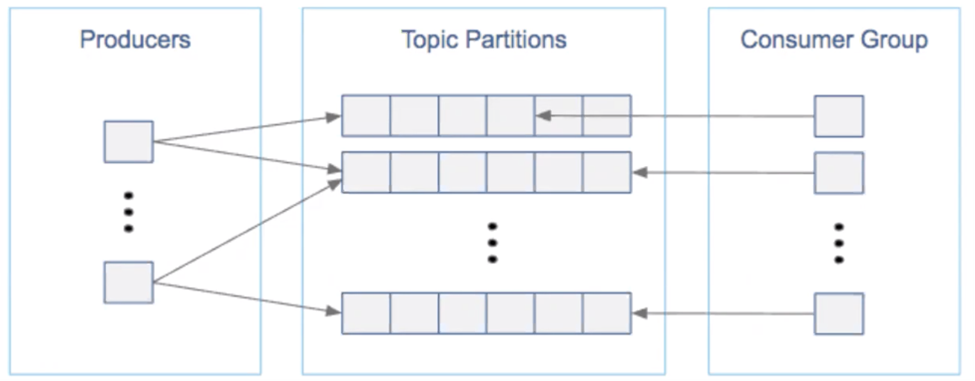
Keep distributed parallel architecture in mind by distributing load, with respect to writes and reads, evenly across partitions. Consider the throughput of producers and consumers you’d like to achieve to estimate the number of partitions you need.
To find the right number of partitions, first calculate the number of producers required by dividing the total expected throughput for the system by the throughput of a single producer to a single partition. Then, calculate the number of consumers by dividing the total throughput by the max throughput of a single consumer to a single partition. Make the total number of partitions equal to the greater of these two numbers.
Remember that you can specify the number of partitions either when a topic is created or afterward. Because the number of partitions affects the number of open file descriptors, be sure to set an appropriate file descriptor limit. Overprovision, don’t underprovision—reassigning partitions gets costly.
Once partitioning is assigned, you can no longer reduce the number of partitions, but you can create a new topic with fewer partitions and then copy over the data. More partitions also increase the pressure on Apache ZooKeeper to keep track of them, using more memory. If a node goes down, more partitions mean a higher latency in partition leader election; for optimal performance, keep partitions below 4000 per broker.
See also: Current 2022: The State of Streaming Data
2) Offline partitions
If a partition in the production environment goes offline, you’ve got a critical condition requiring a critical alert. An offline partition usually means that a server has restarted or a critical failure has occurred. In a Kafka cluster, one broker takes leadership duties to manage and reassign partitions as necessary. An offline partition happens when that elected leader partition dies. Without an active leader, the partition won’t be readable or writable, which could mean losing messages.
To prevent the damage of this state, monitor these three key metrics: 1) OfflinePartitionCount, 2) ActiveControllerCount, and 3) GlobalPartitionCount. OfflinePartitionCount is the number of partitions without an active leader. An alert should be sent if this metric has a value greater than 0. ActiveControllerCount is the number of active controllers in the cluster, and should alert if the sum of all brokers is any number other than 1. GlobalPartitionCount is the total number of partitions in the cluster.
Read the rest of this article on RTInsights.







