




This article is sponsored and originally appeared on Ascend.io.
Data pipelines are having a moment — at least, that is, within the data world.
That’s because as more and more businesses are adopting a data-driven mindset, the movement of data into and within organizations has never been a bigger priority. As the primary mechanism for implementing data-first business models, data pipelines have moved into the spotlight.
But with data engineers in short supply and cloud costs rising, how can data teams possibly keep up with the growing demand for accessible, trustworthy data?
Although every company has unique data challenges, there are several near-universal data pipeline best practices that can guide every data leader in building a solid foundation with their team. In this article, we’ll walk you through these pillars for your comprehensive operational strategy to deliver trusted business value from your company’s data.
Defining data pipelines and their role in the modern business
First things first: let’s define what exactly data pipelines are, and how they function within a modern business. A data pipeline is a method for transferring data from many sources to any number of destinations, such as data warehouses or business intelligence tools. Along the way, a pipeline transforms the data step by step to meet the business requirements of the users at the destinations.
For example, you can use a data pipeline to move customer purchase history from a data warehouse into a customer relationship management (CRM) system. This allows business users to access historical customer data in a familiar system and make more informed decisions during customer interactions.
We may be biased, but it’s nearly impossible to overstate how important data pipelines have become to modern businesses. Data pipelines are the lifeblood of moving information among systems, teams, and even other companies. Finance, marketing, operations, customer success, sales — everyone relies on accurate, trusted data to do their jobs and make decisions on a daily basis. That data appearing in the right place, in the right format, at the right time — it all depends on data pipelines.
Ultimately, well-running data pipelines make it possible for business units across the organization to access, combine, analyze, and visualize shared data with a high level of integrity. This gives your business leaders the insights they need to make more informed, data-first decisions.
See also: The Evolving Landscape of Data Pipeline Technologies
The challenges and complexities of data pipelines
Unfortunately, building and maintaining a quality data pipeline program is easier said than done. Setting up one or two pipelines may be straightforward, but over time, business users develop a hearty appetite for data — and that means a complex network of data pipelines, working seamlessly together to keep applications and decision-support tools populated with fresh, reliable data.
This complexity carries significant challenges, such as:
- Developing an effective data pipeline program with scalable processes that extract value from data
- Building the right infrastructure, platforms, and tools to support the data pipeline program
- Finding the right technical talent and gaining the right skills on data teams
- Managing risks such as inconsistent data, out-of-date data, unreliable data, etc.
Our research has found that to meet these challenges, data engineers and data leaders can adopt best practices associated with better outcomes: faster delivery of new pipelines, better team productivity, higher pipeline reliability, better data integrity, and lower operational costs. Let’s dig into the details.
Data pipeline best practices
Best practice #1: Adopt a data product mindset
Many data teams focus on technology, building a data stack or troubleshooting urgent technical issues — causing them to overlook the broader business challenges their data pipelines were initially designed to address. By adopting a data product mindset, you can align your team on designing and building pipelines that better deliver on their purpose of achieving meaningful business outcomes.
Data products are assets specifically designed to help businesses and data consumers make better decisions, improve processes, gain insight, and generate value.
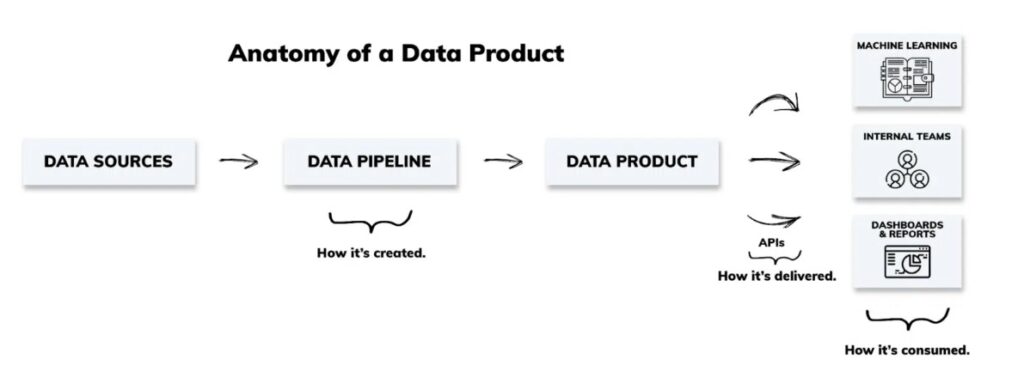
Practically, this means data engineers have a clear understanding of their pipelines’ intended functionality (usability, accessibility, and relevance) and format (dashboards, reports, and datasets) before they start building.
Product-minded data engineers start by finding the answers to key questions, such as:
- What do end users want from the data?
- What will they use it for?
- What sort of answers do they expect from the data?
Naturally, this work doesn’t happen in a vacuum. Just like traditional product development, adopting a data product mindset requires strong cross-functional collaboration among the data consumers, the data owners or stewards within the business domain, and the data professionals developing the product.
As data leader Zhamak Dehghani describes data products, “Analytical data provided by the domains must be treated as a product, and the consumers of that data should be treated as customers — happy and delighted customers.”
With a customer-first, data-as-a-product mindset, building pipelines becomes a highly intentional action with a singular focus on extracting and providing as much value as possible.
Best practice #2: Prioritize data integrity
If you want to facilitate data-driven decision-making, your executives and business leaders need to feel confident that your data is valid, accurate, reliable, and can be trusted. That requires a comprehensive strategy for ensuring data integrity at every step of the pipeline.
As inherently sequential operations that deliver actionable steps in measurable stages, data pipelines present an opportunity to ensure integrity throughout the data lifecycle. Rather than waiting until the end of the pipeline to check for dimensions of validity (like the correct format, schema, storage, and cadence) or accuracy (like completeness, uniqueness, and consistency), the best practice is to build those quality checks into every step of the pipeline.
Data pipeline automation makes data integrity more achievable at every stage of the lifecycle (more on that below), and greatly reduces the amount of manual intervention to those edge cases where human knowledge is needed, such as certain deduplication or error conditions. In addition, sophisticated data profiling tools can detect previously unknown problems in the data, and provide the filtering criteria that can be applied in the data pipeline flow to prevent them going forward.
Best practice #3: Embrace constant change
Change is unavoidable for data teams. Business logic evolves. New data sources emerge. And pipelines need to be adaptable enough to propagate change and support new functionality.
For example, let’s say you have a pipeline that uses data from a weather forecast to notify a business unit when bad weather threatens its ability to fulfill product orders. When you initially build the pipeline, the definition of bad weather only applies to a Chicago warehouse — so a forecast of greater than eight inches of snow triggers a notification.
But when your company opens an additional warehouse in Houston, the definition of “bad weather” would be fundamentally different. For instance, you need to notify the business unit when excessive winds indicate the possibility of a hurricane. If your pipelines aren’t designed to adapt to these changes, your engineers are likely to build distinct and separate instances, raising operating and maintenance costs for years to come.
Change constantly happens to the business logic in your pipelines. Your methods should anticipate future changes as part of your standard practices, and choose technologies that enable human intervention with minimal impact on day-to-day operations.
Best practice #4: Plan for non-linear scalability
One of the most common problems we’ve seen data leaders face is the demand for resources to maintain data pipelines once they’re built.
Let’s say one data engineer builds five pipelines for a startup. As soon as they are launched, requirements and data sources begin to change (see “Embrace constant change”). Since that person is the only one who knows the details of those constructions, it takes most of their time from then on to maintain those pipelines. To build the next five pipelines, the company has to hire another data engineer, and then another, and then another. This linear scalability is unsustainable, especially given the current shortage of data engineers in today’s job market.
Instead, with a bit of forethought and not much additional investment, teams can plan to grow their data pipeline programs with non-linear scalability. That means each new batch of pipelines take much less effort, time, and resources to build and run.
Non-linear scalability requires good DataOps processes. As data leader Prukalpa Sankar describes this new framework, “DataOps is a mindset or a culture…Its principles and processes help teams drive better data management, save time, and reduce wasted effort.” By applying Lean, Agile, DevOps, and data product methodologies to data operations, data teams can work more efficiently and save valuable time.
Data pipeline automation is interwoven as the enabler for DataOps methods and the ability to shift the productivity of data engineers. By relieving busy work and break-fix cycles in the tech stack, automation frees up more of the team’s engineering capacity to drive the non-linear growth of the pipeline program.
Best practice #5: Plan for maintainability
Embracing change and planning for scalability also means embedding maintenance and troubleshooting as a standard practice. Instead of treating them as occasional exceptions, monitoring, detecting, and addressing issues should be part and parcel of any data pipeline program.
One effective strategy is to identify and standardize the common, rote, and complex coordination tasks involved in the ongoing maintenance of data pipelines, and to remove the risks by automating them. Modern data pipeline automation technology can constantly detect changes in data and code across complex networks of data pipelines, instantly identify all the impacted areas and operations, and respond to those changes in real time. Adopting automation as a best practice can include the propagation of change in data and code, and enforcing data quality rules during processing (see “Prioritize data integrity”). Data pipeline tools should empower human intervention to help teams resolve maintenance issues that stump automation.
Data teams should accelerate their engineering velocity by reducing the cycle time of maintenance tasks with data pipeline automation to handle common maintenance processes like:
- Pause and resume – ability to stop processing at very specific points in the pipelines, without affecting any other running pipelines and throughput. Release of that pause automatically picks up and integrates the resumption into the ongoing flows of data without any further manual tasks required.
- Retry failures – awareness of the many possible failure modes in data clouds, networks, infrastructure, data interfaces, and applications, and intelligently retry the specific failure points without halting the pipelines or requiring manual intervention.
- Restarting without reprocessing – when a pipeline is started from any type of stop or pause, minimize the reprocessing of data sets or processing steps to resume normal operation.
- Pipeline linkages – automatically propagate data and changes through sequential networks of data pipelines, as if they were a single, continuous network. Seamlessly apply all other automation throughout linked pipelines, such as pause and resume, retry failures, restart without reprocessing, incremental change, and more.
- Incremental change – process all data incrementally to reduce reprocessing across the entire network of linked pipelines.
- Pipeline rollback – upon errors in maintenance or programming, enable engineers to roll back the entire pipeline network to the last known incremental state with a single operation — without requiring any additional cleanup or synchronization tasks.
- Stop propagation at data quality failure – upon detecting a data quality error in a data pipeline, gracefully stop that pipeline at the point of failure to prevent propagating bad data — while all other data flows continue unimpeded.
Automation of these maintenance processes dramatically improves the ability of engineers to intervene quickly, resolve problems efficiently, and resume normal pipeline operation with minimal downtimes.
Take the next step toward building better pipelines
Following these data pipeline best practices will help any team deliver data pipelines with the integrity needed to build trust in the data, and do so at scale. They must also be tightly woven into the fabric of data pipeline automation to achieve non-linear productivity for a data team, and for each additional team member to contribute outsize results.
Take the next step toward building better pipelines and check out our latest “What is data pipeline automation?” whitepaper and discover exactly how organizations can reduce costs while creating more value from data through automation.







