



Data migration, in its simplest terms, involves moving your data from one cluster to another cluster. In this article, we’re not talking about ETL or ELT, we’re talking purely about extracting data and changing its context, not the actual data itself.
In this case, locality is the primary context. Data has different characteristics that sometimes change, and we want to move it to a place reflecting that change. So, it’s not about moving from state A to state B; it’s about the state of movement.
Core engineers and infrastructure engineers need to think about this and plan for the “state of migration,” the in-between space where data is difficult to maintain during transit.
See also: Re-examining the ETL vs. ELT Conversation in the Age of Cloud Analytics
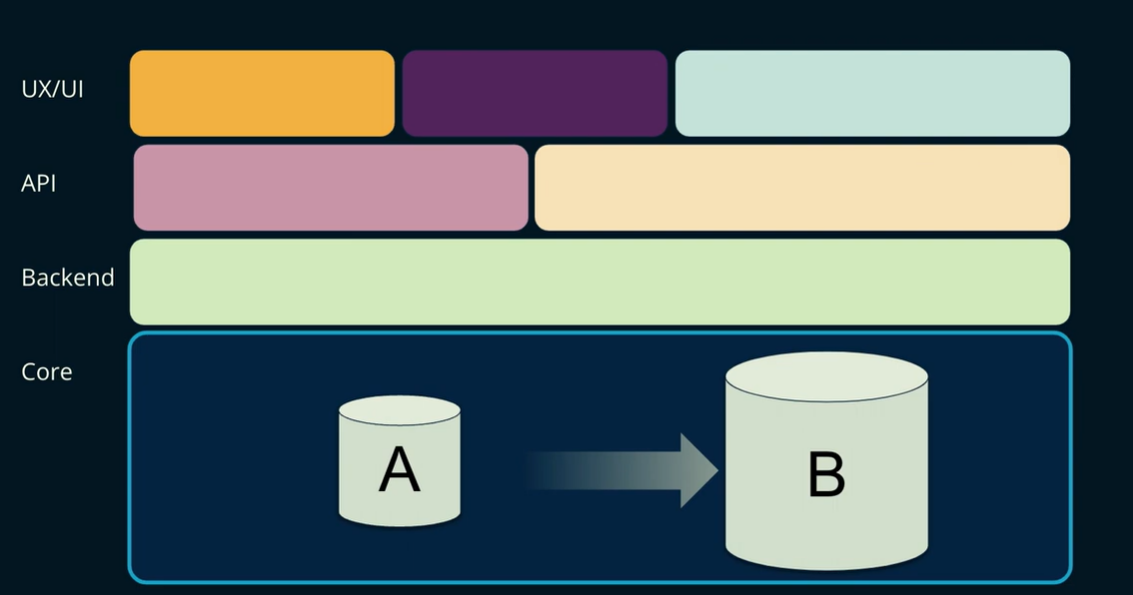
There are four fundamental methods for moving data between clusters. When we talk about our infrastructure, it starts way down in the core. Above that is the back end layer, followed by an API layer, and hovering over that is the front end and application layer.
Context changes in data calling for cluster migration
Context changes in data are rare, but they’re unavoidable. The dynamic nature of business itself means you’re either in the process of migrating data from one cluster to another, or you’re planning for it, and all of this requires expertise because it’s both complex and rare.
Whether or not you want to migrate data between clusters, there are many cases where a change outside your control will require this process to take place. Most commonly, these are changes in data throughput or usage characteristics in clusters fine-tuned for different characteristics.
Other less common but possible changes that require data migration between clusters are:
- A change in ownership of the cluster but not the data (such as moving between SaaS and self-managed environments).
- An organization-wide change in the underlying infrastructure (such as moving between cloud providers).
- Changing the geographic position of the data due to regulations (such as GDPR requirements).
The speed of change in your core infrastructure will always be slower than front end changes, where things happen very quickly. This makes planning for inevitable changes in the state of data moving from one cluster to another very important to maintain data integrity.
Four migration methods
There are four migration methods in this article. The first is re-indexing, followed by the snapshot/restore method, and the cross cluster replication method. The fourth doesn’t have a formal name, so I will refer to it as “the node toss.” It may not warrant having a name of its own, but maybe you’ll agree with me that it’s important to know about it.
1. Re-Indexing
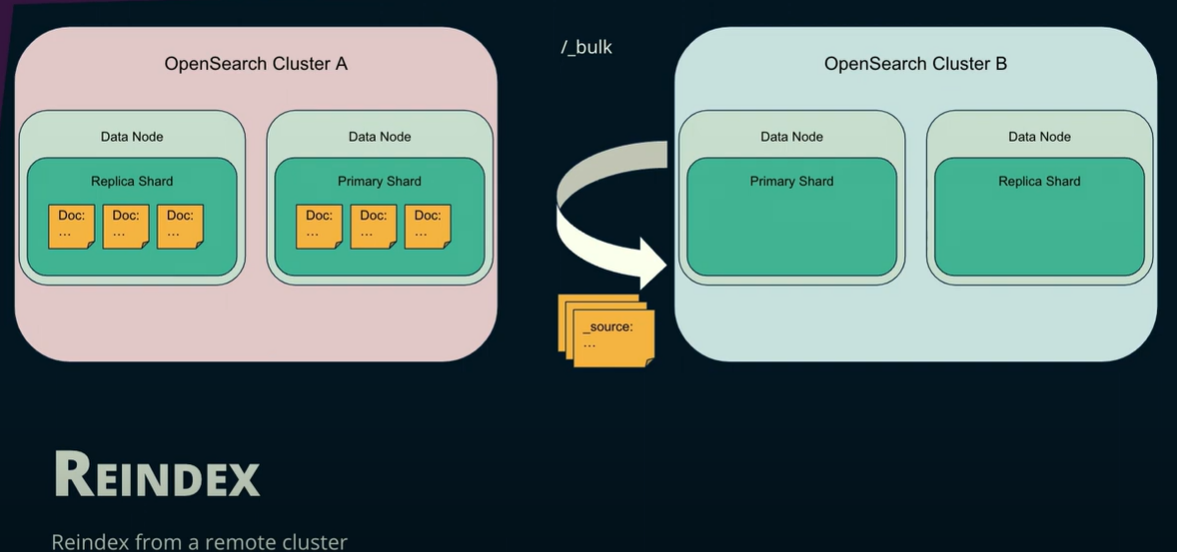
Re-indexing from a remote cluster extracts data from within the cluster by creating an index and running a scroll query. This extraction happens very slowly, and only the data in the scroll context will be read. This means if new data comes in once the reindex has started, it will not be moved.
The source needs to be stripped away from each of the docs retrieved, and then the cluster uses the bulk indexing API to index the data into itself.
What’s unique about the re-indexing method is that you have the capability of manipulating the data before it gets to the destination.
This method is the slowest way to move data, even within its own cluster, so it’s best to use this method only when working with a small amount of data.
2. Snapshot/Restore
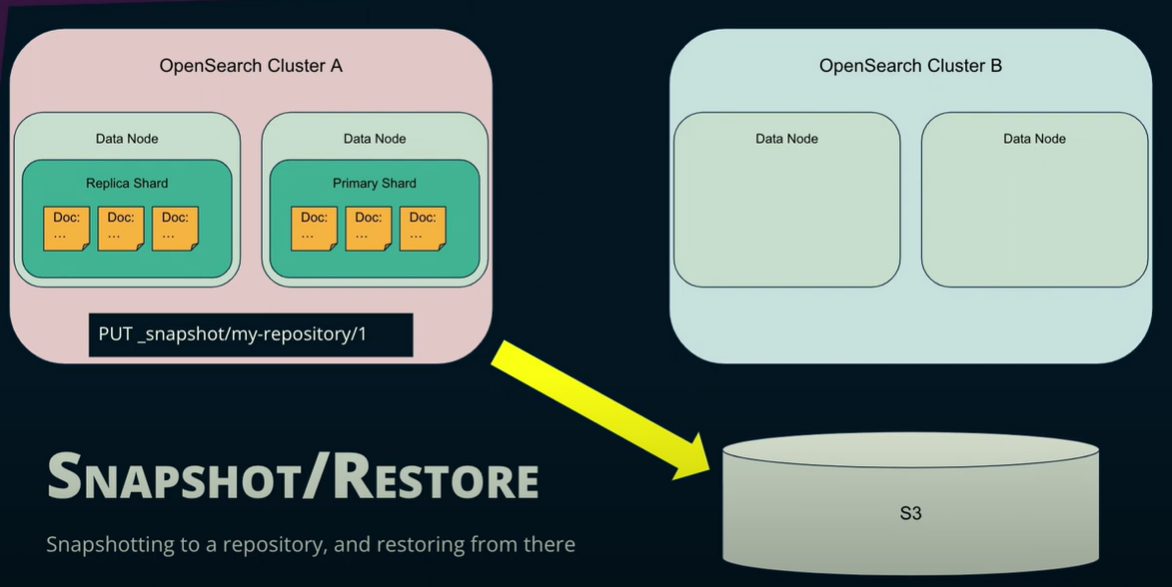
Snapshot/restore is the easiest method for data migration between clusters. All you do is snapshot the data to a repository, add the repository in the destination cluster, and restore it there.
With this method, your data typically becomes somewhat stale because of the time that passes between the snapshot start time and the restore end time. This method, on its own, is not the best option for log ingestion cases since that delta will always exist.
There is a lot of tooling available to help make your data less stale in the snapshot/restore method. You could have your data go to both clusters simultaneously while you’re doing the restore, followed by some de-duping of the data you’ve snapshotted already and also flowing to both clusters simultaneously.
It’s helpful to mention that when you’re restoring, you’re taking the data as it was in the previous cluster; settings, template, everything. The same files will be stored.
3. Cross Cluster Replication
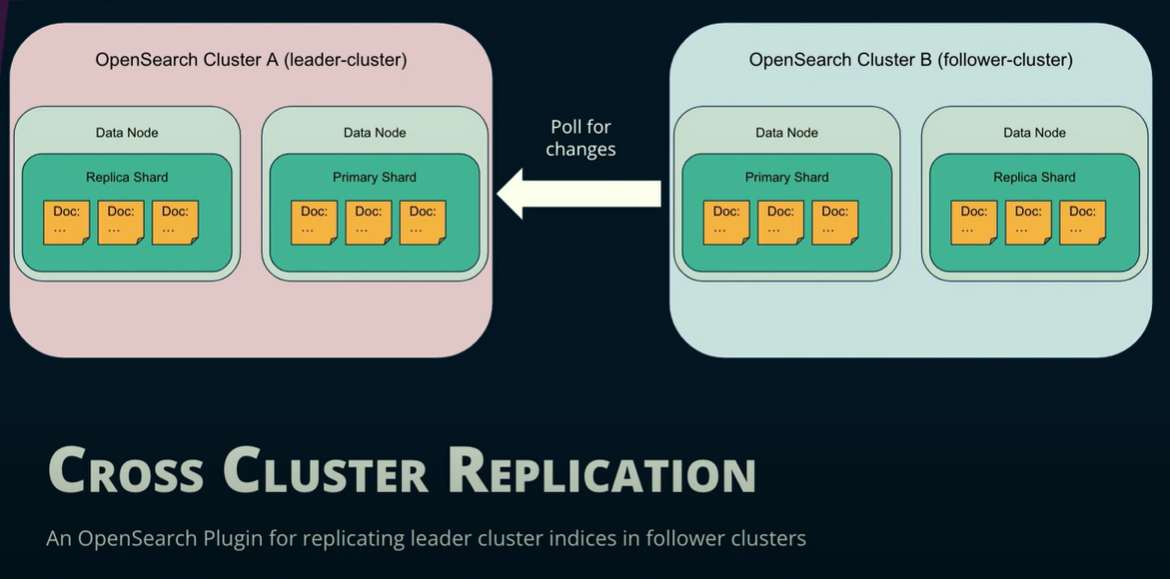
Cross cluster replication is an easy-to-setup plugin. You have two clusters: the leader, which is our source, and the follower cluster. The plugin is going to recognize those nodes and use a rule to set up an index using all the existing settings. It will get changes from the translog and replay them.
The leader and the follower are identical. The gap in time that exists with the other methods doesn’t exist in cross cluster replication so your data is going to be (nearly) live. Stopping the cross cluster replication requires a few more API calls.
4. “The Node Toss”
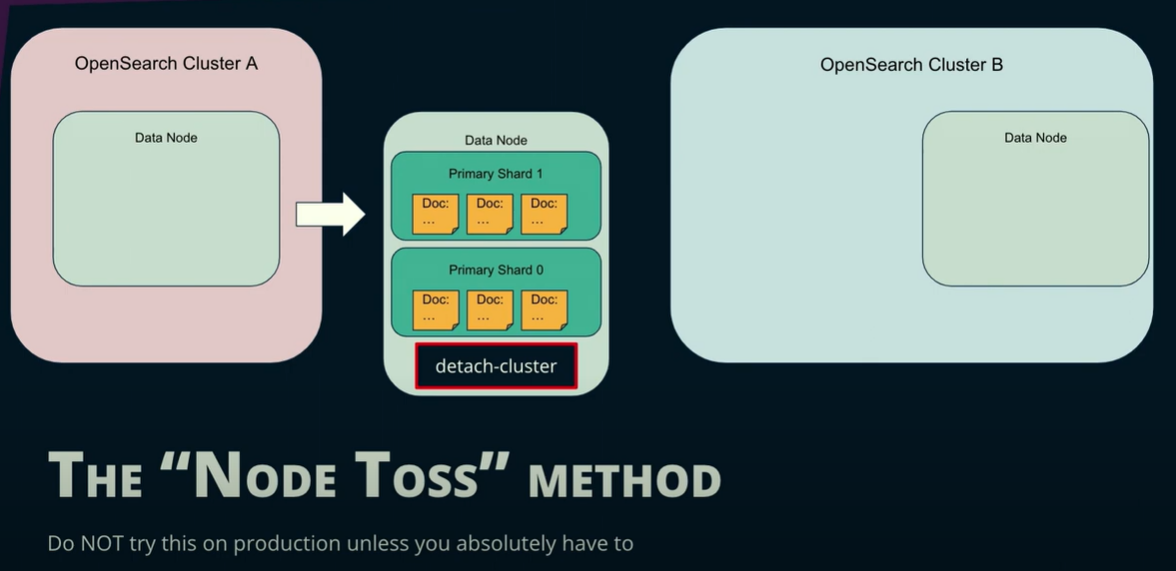
*Risk of arbitrary data loss*
If all cluster managers are gone and everything is up in the air, and you have no other options, you might want to consider the “node toss” method.
To prepare a node for this method, you need to put all of the shards you want to migrate on one node in the original Cluster A. Then you stop it and run the ‘detach-cluster’ command. The detach-cluster command will remove a UUID that identifies it as part of the first cluster, changing its settings.
Now, the node is in the air (tossed!), without any cluster of its own. In the opensearch.yml file of this node you set it to be part of Cluster B, and then you restart it, and it’s “caught” by Cluster B. Then you would have to run the ‘import dangling indices’ API for the indices on the node and if you’re lucky, it’s actually there as a part of Cluster B.
See also: Game of Protocols: How To Pick a Network Protocol for Your IoT Project
Different use cases call for different methods.
- Data liveness: Cross Cluster Replication, or if the cluster is in a devastating state then the “node toss” to bring the data back.
- Cluster ownership: No great answer here, but most likely data won’t go between clusters in this case but rather from raw archive to the new cluster. Though, depending on the type of relationship with the other party you may consider working together with the Snapshots method.
- Additional processing: Out of all the methods only Reindexing currently provides this capability. For speed you may consider transferring the data using another method and processing it in its destination, or the other way around.
The state of change brought on by data migration due to a context change is a specific and delicate set of processes that require certain expertise. At the same time, core and infrastructure engineers can be confident that one of these four methods for migrating data between clusters will work to support the quick and secure movement of data.
Just watch out for that node toss method–it’s kind of like throwing caution to the wind.







