
Several years back, the application technology industry had this concept of breaking big applications up into smaller independent components, microservices, and deploying each in its own container. The container idea has some pretty cool advantages it turns out:
- Automated deployment was a huge advantage, especially on public or private cloud infrastructures. Fast deployment without human intervention made containers incredibly useful, especially for elastic scaling.
- Unlike a VM that had to carry around its whole operating system, containers were nimble, small, quick to deploy, and efficient to execute. Containers offer fine-grained control over resource allocation and more efficient use of computing capacity.
- Containers could deploy anywhere, from my laptop to a giant mega-server to any cluster or cloud. They were completely infrastructure agnostic, providing the ultimate in portability.
This isn’t even a complete list of the advantages, so it’s clear there are some solid reasons for containerization. But to get all these advantages wasn’t always a simple matter. To make this happen, every individual action within an application had to be broken down into an independent mini-app, aka microservice, that did one thing only.
See also: Unifying the Data Warehouse and Data Lake Creates a New Analytical Rhythm
From one big monolith, applications needed to be decomposed into lots of little microservices. Each of these was put in a container with all the other bits it needed to do its job. Technologies like Docker provided the containerization. The container copies used REST or some other API layer to talk to each other. An application like Kubernetes or Docker Swarm controlled it all like the conductor of an orchestra.
Microservices in a container had to be able to be independently deployed, do their thing, and be destroyed again. Being ephemeral was essential to containers. This imposed certain restrictions. In particular, there were two important aspects to each microservice in its little independent container:
- It did its job without worrying about the other containers. It had no need to keep track of where it was or where the other application components were. It didn’t need to know what things were like before it began and no need to preserve anything about where it ended – it was stateless.
- It didn’t persist anything. Once it did its job, that particular instance of the microservice could disappear. There was no need for it to, for example, store data long term. If it modified data, it stored that in a database, and the database worried about persistence.
Normally, copies of containers would be created in a pod, a sort of super-container that could contain as many containers full of microservices as needed to do a single job. Each pod would do its thing, then be automatically disposed of. If you need more computation, more pods are created, the ultimate in automated elastic scaling.
This concept is brilliantly useful for many applications and allows the exact same application to work across almost any environment, the ultimate in portability.
However, there’s a huge bastion of essential enterprise software that this doesn’t seem like a good idea for databases. Microservices in containers affect data in databases. You don’t put databases in containers for good reasons. What two things does a database need to do?
- It needs to move data around, retrieve it, analyze it, and make changes while keeping careful track of what it did and the current and past states of things. It’™s pretty much the opposite of stateless, aka stateful.
- It needs to persist data for essentially, forever, unless someone specifically deletes it.
Plus, databases are the ultimate monolith, the epitome of applications that were absolutely never meant to be broken into little stateless microservices and containerized.
Except that, they also need to scale efficiently. They also need to deploy pretty much anywhere and to be deployed rapidly and automatically. They need both portability and elastic scaling, and containers are the best way to accomplish those goals.
Databases need the advantages containerization brings, especially if the database is deployed in more than one place. If, for example, a database works only in one particular cloud environment or only on one kind of hardware, that would be different. Ironically, databases that work with containers are sometimes called cloud-native, even though they can often only work in one cloud, which negates one of the advantages of containerization.
Analytical databases need to be infrastructure agnostic. Hybrid ‘“ part on-prem, part cloud ‘“ is the most common enterprise deployment situation for analytics today. Hard to have a hybrid deployment if your database only works in one place. What about multi-cloud? What about specialized hardware or smaller boutique clouds beyond the big three? All of these deployments are the ideal deployment for some companies. If a containerized “cloud-native” database only works on one cloud, it can’t be used for other deployment options.
Where there’™s a need, someone will build the software to meet it.
Hence, Kubernetes StatefulSets was invented. What is StatefulSets? Well, normally, containers are deployed using a Kubernetes capability called, unimaginatively enough, Deployments. Each container instance in its pod is created, does its thing, and is destroyed using Deployments. All the pods can be created by Deployments at once, and they are assigned a random identity since it doesn’t matter which pod does what.
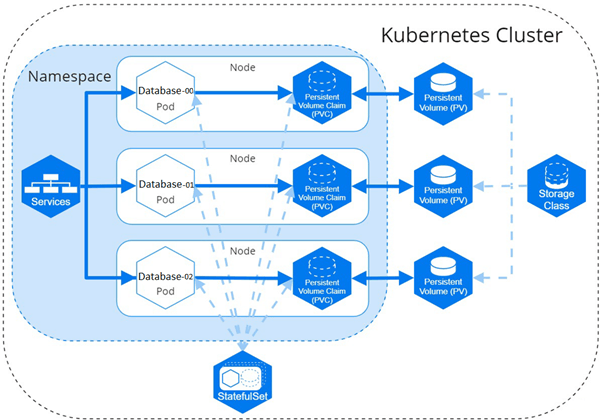
StatefulSets instantiates each pod with its own unique identifier, named for the type of database and a number starting at 0. The pods are created in a careful sequence, with the second only being created after the first is up and running. Each pod is given a data volume connection ID (PVC) assigned to a separate persistent data storage location (PV) that acts as a cache to speed analytics by shortening network latency, so every query doesn’t have to retrieve data from the main object storage.
One of the reasons databases can be containerized is that many now have the capability to function with data and compute separately to accommodate shared cloud storage architectures. This means that if the pod or a whole node in a cluster goes down, the data storage – completely separate – does not. When Kubernetes instantiates a new pod, it is assigned that same pod identifier and data storage connection ID (PVC), so it attaches to the same data storage volume (PV) using that PVC. This allows data to persist, and it allows the database to keep careful track of changes made to that data – exactly what a good database needs.
Kubernetes Statefulsets also provides the most essential advantages of containerization – automated deployment, elastic scaling, and freedom of infrastructure – without the stateless restriction.
With StatefulSets, databases are an application type that can and should be containerized.







