




This article is sponsored and originally appeared on Ascend.io.

Creating business value from the onslaught of data can feel like captaining a high-tech vessel through uncharted waters. Data teams across business areas are cranking out data sets in response to impatient business requests, while simultaneously trying to build disparate DataOps processes from scratch. Tools are proliferating, cloud bills are soaring, hiring can’t keep up, and the return on investment is cloudy at best. No doubt, we’ve all felt the sting of expenses and teams going rogue.
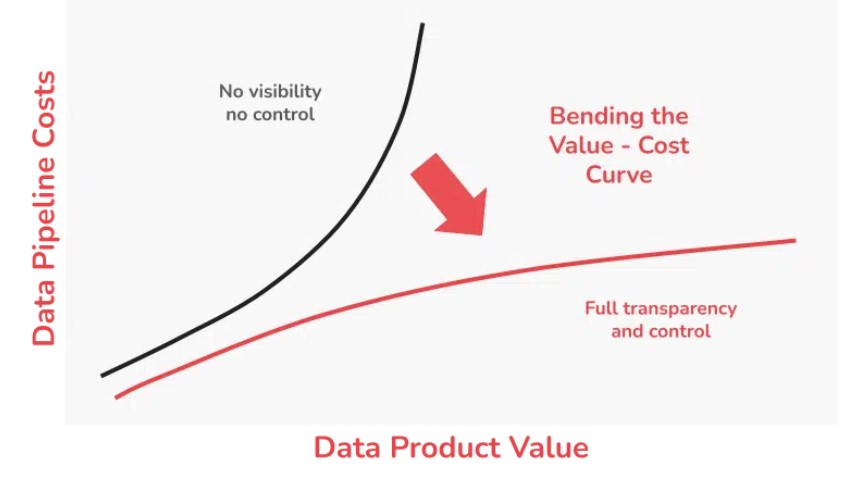
In this article, we focus on the financial consequences of this activity and introduce common sense methods that help you get a grip on costs. Our guiding principle is that full transparency of your data costs must be tied to data products and the business value they create — so that you can make informed decisions based on return on investment. That provides the clarity for your own prioritized roadmap of where to improve business value, performance, and efficiency, and implement savings that permanently bend the value-cost curve in your favor.
- Delivering Business Value Through Data Products
- Costs of Data Products
- The Tools in the Data Stack
- Staffing
- Infrastructure
- Intelligent Data Product Costing – The Ascend Advantage
- Costs by Infrastructure Provider
- Cost Allocation to Data Pipelines
- Cost Allocations to Individual Transform Steps in Data Pipelines
- Using Observability to Tune Your Pipelines
- Controlling Costs with Agility
Delivering Business Value Through Data Products
Before we dig into costs, let’s get our arms around the value creation of data products. Think of data products like you would any other business process outcomes. The real value comes from how they’re used in day-to-day operations and transactions with the product. Just like any other product, they should drive goals we can measure, so we can track their effectiveness in the overall success of the business. Below are 5 key business objectives commonly driven by data products:
- Quality of Decision-Making: Data products such as reports, dashboards, and alerts are usually at the center of making better business decisions. When you measure the improvement in the quality of such decisions, be sure to include the attribution to the specific data products that played a role.
- Revenue Impact: Often, increases in revenue can be attributed to data products directly (e.g., selling of data products) or indirectly (e.g., insights leading to improved customer satisfaction, which in turn drives sales).
- Cost Savings: Insights derived from data products can directly lead to cost savings in the business. Examples are rationalization of supply chains, decreased labor costs, or reduced costs of sale due to improved customer engagement.
- Risk Reduction: Data-centric decision-making can also contribute to risk reduction. Examples include regulatory risks (through better monitoring and compliance) or reduced business risks (through improved visibility into business operations).
- Competitive Advantage: Many data products give organizations a competitive edge with quicker, more accurate market insights and more precise decision-making.
You can use common methods to financially quantify improvements in business objectives and easily attribute them back to the individual data products that were used to achieve them. One modern method to assess the value of a new data product, or a potential change to an existing one, is to create lightweight prototypes and assess their potential value in real operating conditions. The most impactful ones can then be scaled up using iterative development practices.
These methods are sufficient to create the return part of the data ROI calculation. Now let’s turn our focus to the costs.

Costs of Data Products
The products of any business are the output of complex processes involving people, technology, and resources. In the case of data products, these are networks of data pipelines, which makes them an integral part of your modern operational machinery. To determine the ROI of any particular data product, you need to attribute the costs of building and running data pipelines.
Unfortunately, there is usually no straight 1-to-1 relationship between data products and the network of data pipelines that creates them. Some steps in the network can incur high compute costs, while others require sophisticated engineering to get right. Some of the steps in the network contribute to some data products, and not others. Attributing costs to each individual data product turns out to be fiendishly difficult.
For example, improving basket value in online transactions by X% may require several data products, such as better web page keywords that drive SEO in search engines or more precise discounting during the product browsing experience. Each of these improvements could be attributed to a separate data product used in the shopping application, but behind the scenes lies a web of interacting data pipelines that produces these data products. Some of these pipelines may include compute-intensive customer segmentation and product affinity ratings, while others are simply current weather feeds, which can drive product demand.
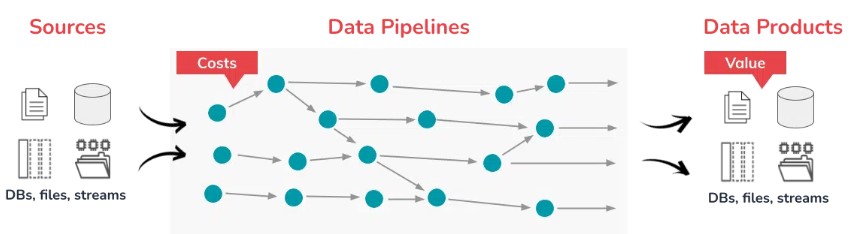
So how do you tie the costs of individual steps in these data pipeline networks back to the individual data products that improved the business?
Let’s begin by looking at the costs of your data pipeline networks in aggregate. The largest expenditures in your data operations are typically staffing, tools, and associated infrastructure. So while data pipelines are an utter necessity for your businesses, in the face of business justification and budgetary pressure, they are also the anchors from which to understand and actively manage your costs.

Let’s dig into each of these costs, and identify some levers with which to tune them and improve their value-to-cost ratio.
The Tools in the Data Stack
Over the course of the last decade, the data industry has fragmented the data pipeline workflow into discrete steps for which targeted tools have flooded the market. As a result, each company reinvents its own modern data stack, buying several of these narrow tools and hiring data engineering specialists to integrate them with custom code.
It is not unusual for these stacks to include separate tools for data connectors, data ingestion, orchestration, storage management, data quality, ETL, reverse ETL, scheduling, and more. In addition to locking up the agility to adjust course, it becomes nearly impossible to allocate license costs, running costs, dedicated expertise, integration, and maintenance costs in order to quantify the cost basis of any particular data product.
The answer here is to adopt a flexible platform that spans these functions uniformly, and that operates on a cost model tied to the running costs of the data pipelines. This way the cost of tooling can be directly attributed to each data product, as we’ll discuss in the next section.
Staffing
Most staffing costs for data teams stem from the fragmented nature of the modern data stack, requiring narrow specialists to build the company’s stack, upon whom the continued operation depends. Their highly technical tasks are often constrained to system internals, with little application to the business requirements that drive the demand for data products in the first place.
The answer here is to relieve the team of building and maintaining complex systems by adopting a unified end-to-end data pipeline platform. This deemphasizes the importance of deep technical specialization and enables teams with broader skillsets of analysts and engineers that are closer to the business. These contributors can distinguish more clearly which data products are moving the needle, and can better align their efforts with business outcomes.
Infrastructure
With the growth of your data operations, the cost of infrastructure to run them becomes a major determinant of your data pipelines. These running costs are heavily dependent on how data products are reused, how intelligently the underlying compute operations are dispatched, and how the high cost of compute is offset with the clever use of cheap storage.
The answer to controlling these costs is to build your data pipelines with the most advanced intelligence available. By intelligence, we mean specific technical capabilities that apply a high level of automation and sophisticated operational strategies, actively minimizing infrastructure costs while delivering data products with integrity and reliability.
This intelligence is also the foundation to understanding the costs of individual data products. It should inherently provide fine-grained metadata about the infrastructure costs of every operation, so they can be allocated to each data product. This allocation mechanism is where we’ll spend the rest of this article.
Intelligent Data Product Costing – The Ascend Advantage
Up to this point, the costs of building and running networks of data pipelines still lack any 1-to-1 relationships to the data products they produce. So how do we bridge this gap, so we can compare the cost of data products with the improvements of business objectives they deliver, and we can make informed investment tradeoffs?
This conundrum is why data product costing is one of the core capabilities of the Ops Plane in the Ascend platform, specifically designed to address the business-critical need of controlling costs and understanding ROI. This capability leverages unique metadata that tracks the running costs of every data operation in every pipeline across your entire pipeline network.
This fine-grained detail of operational costs enables cost attribution for each operation in the data pipelines to each data product. These costs include those incurred in the infrastructure that engineers choose for each pipeline, as well as the cost of the Ascend platform itself, greatly simplifying the ROI calculation.
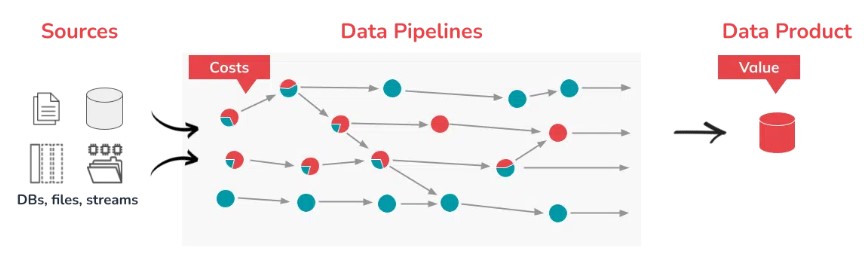
These costs can be viewed directly in the Ascend platform, as well as accessed through the SDK. Let’s dig into what this actually looks like, and how easy it is to use.
See also: High-Performance Data Pipelines for Real-Time Decision-Making
Costs by Infrastructure Provider
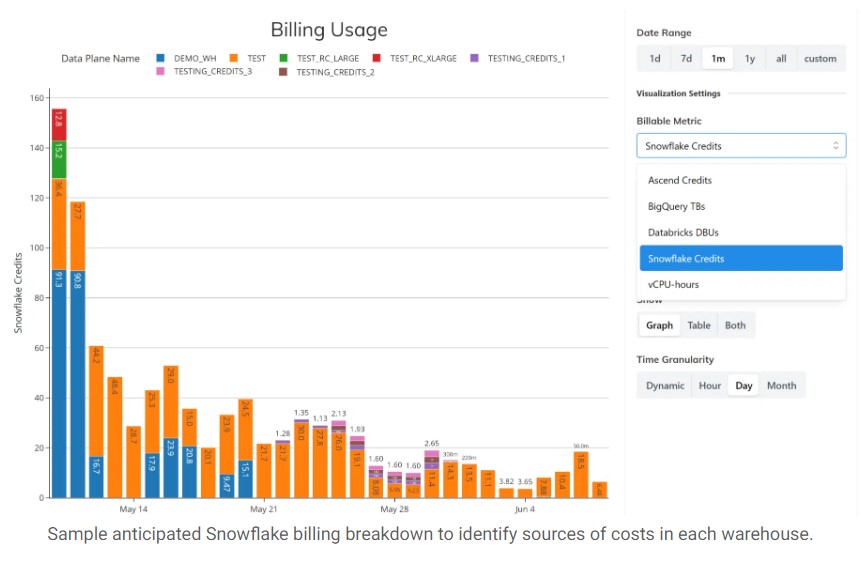
The place to start with the costing of data pipelines is the expected billing amounts from each infrastructure provider. The Observability panel in the Ascend platform includes several reports and charts that show Snowflake credits, Databricks credits, BigQuery units, and Ascend compute credits that can be sliced and diced by time, by pipeline, by infrastructure provider, and even down to the infrastructure data plane, such as a Snowflake warehouse.
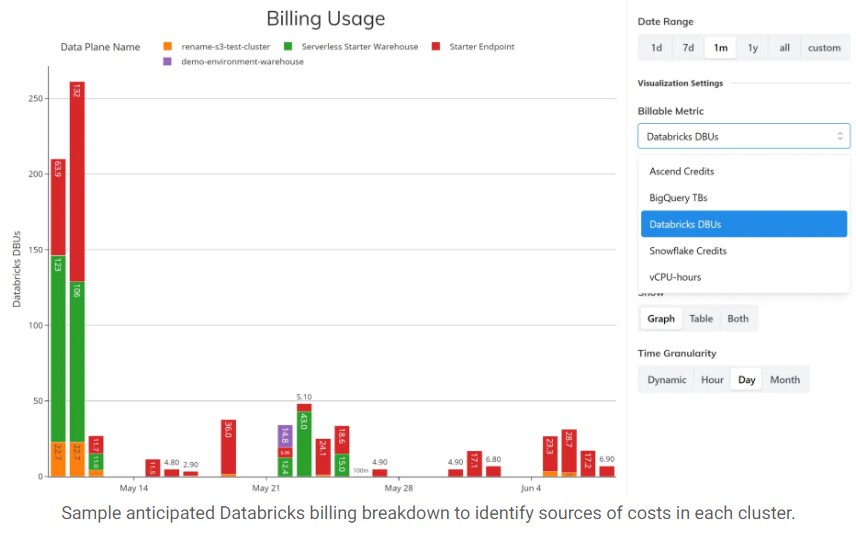
Cost Allocation to Data Pipelines
For the next level of detail, the platform breaks down the detailed usage of resources to each data service (a group of pipelines per infrastructure provider), each dataflow (an individual data pipeline), and each component (a transformation step in a pipeline). The type of resource depends on the infrastructure: Execution Time and TB Scanned for Snowflake, vCPU-hours for Databricks, Task slot seconds and TB processed for BigQuery, as well as vCPU-hours for open-source Spark.
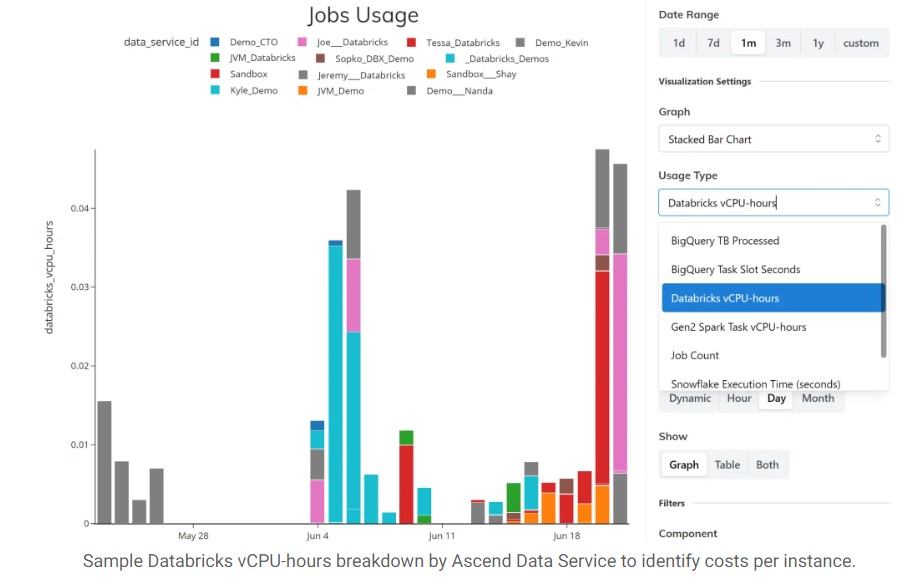
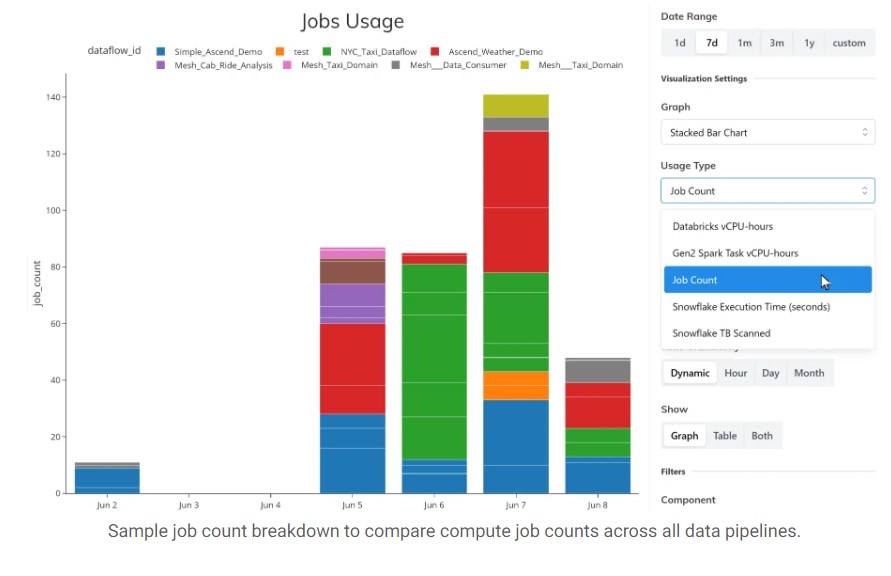
Cost Allocations to Individual Transform Steps in Data Pipelines
Finally, the platform provides all the resource consumption data in a form that stitches together which processing costs contribute to each data pipeline on each infrastructure provider. Users can access this usage information via the SDK, and the platform includes a Starburst graph that shows how it all fits together. The outer ring shows the individual components, the second ring groups them by dataflow, and the inner ring groups those by data plane.
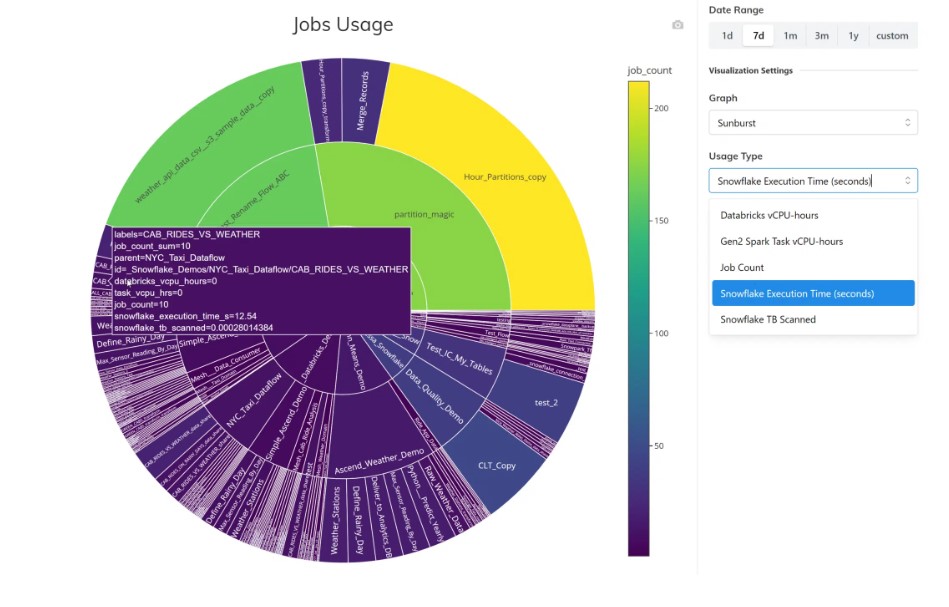
Using Observability to Tune Your Pipelines
With full transparency at your fingertips, Ascend provides the information you need to easily reconcile your data pipeline costs with the value of the data products they generate. Your data pipeline operations become an investment that not only enables actual return on investment, but also helps you incentivize other elements of productivity. The information serves as the roadmap of where to improve performance, efficiency, and savings to permanently bend the value-cost curve in your favor:
- Operational Efficiency: Data pipeline operations can be assessed for efficiency. Hallmarks include the fraction of engineers supporting existing pipelines versus building new ones, the degree of automation eliminating previously manual processes, the number of integrations between tools, and the number of new pipelines being launched per week.
- Cost Savings: Quantify the costs that the data pipeline operation is reducing with automation and tuning. This can be measured in reduced cloud infrastructure costs or decreased labor costs per pipeline.
- Scalability: Data operations should scale non-linearly with growing data pipelines and insights. This means the incremental cost of each additional pipeline should decrease significantly as their number grows, especially with regard to staffing and tooling, but also as DataOps becomes more automated.
- Time to Value: The speed at which each data pipeline starts generating valuable insights is a critical factor. Build and launch times should be measured in hours or days, especially for initial prototypes to discover the value of the resulting data products before investing further to tune and scale the winners.
Uptime: Data operations are central to running any modern business, making uptime a critical element of data pipeline operations. With modern non-stop cloud infrastructure, this metric is not about CPUs or networks. Instead, this should be measured by the ability of pipelines to meet their delivery time requirements.
Controlling Costs with Agility
In addition to guiding the data team to the right places to tune their data pipelines, the ability to pinpoint costs is also fundamental to developing new data products with agility.
Teams paying for the tools and maintenance of opaque data stacks are grounded by the costly baseline for the entire data operation that is difficult to allocate to individual data products. This leads to the disqualification of experimental pilots and smaller projects because their outcomes are unknown, and can’t justify the bulky costs of getting them started. Only big projects for which the value is clear get approved, and often these projects are executed in their own silos, fragmenting the data landscape and preventing reuse of existing data assets. This materially locks up the agility of the business.
Good data product costing on the other hand enables a data team to quickly launch prototype data products, test and measure their business impact, and simultaneously develop a preliminary understanding of the incremental operating costs for the changes to the underlying data pipeline network. There is your ROI calculation in a nutshell, and the basis for continued investment to scale and tune the pipelines with confidence in their value.
Read more about how to use the Ascend features to optimize your data pipelines and reduce costs of your intelligent pipelines even further.







