




This article is sponsored and originally appeared on Ascend.io.

A star-studded baseball team is analogous to an optimized “end-to-end data pipeline” — both require strategy, precision, and skill to achieve success. Just as every play and position in baseball is key to a win, each component of a data pipeline is integral to effective data management.
In baseball, each player’s role, whether it’s batting, fielding, or pitching, contributes to the outcome of the game. Similarly, in data, every step of the pipeline, from data ingestion to delivery, plays a pivotal role in delivering impactful results. In this article, we’ll break down the intricacies of an end-to-end data pipeline and highlight its importance in today’s landscape.
Understanding the End-to-End Data Pipeline
An end-to-end data pipeline is a set of data processing steps that manages the flow of data from its ingestion to its final destination, all within a single pane of glass. Unlike fragmented data pipelines that rely on multiple tools and platforms for different steps, the end-to-end approach streamlines the entire process.
Relying on multiple tools for various steps introduces miscommunication and inefficiencies. The end-to-end approach, on the other hand, ensures a continuous flow of data and removes the intricacies of navigating disparate tools.
This synergy promotes efficiency, precision, and agility in data operations, paving the way for rapid insights and informed decisions. Analogous to baseball, where coordinated teamwork and tactical strategies culminate in dynamic, game-changing plays, an end-to-end data pipeline orchestrates data processes with precision, giving timely and impactful results.
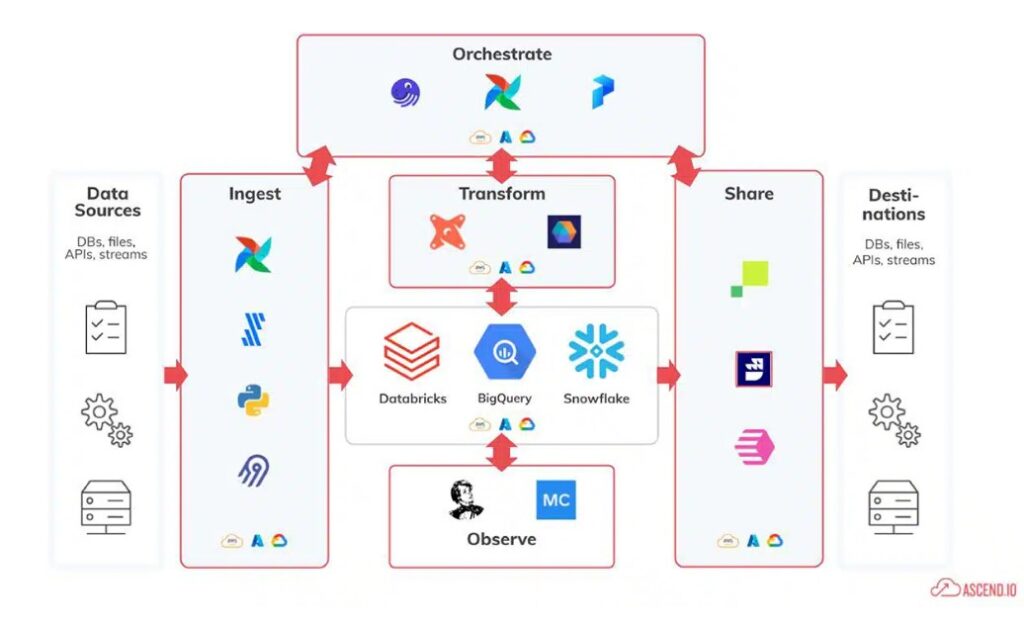
A visual maze: The tangled web of disparate tools commonly used in fragmented data pipelines.
Here are the central stages of an end-to-end data pipeline:
- Getting in the Game – Data Ingestion: Just as a baseball game starts with the opening pitch, the data journey begins with data ingestion. Data is ingested from various sources, like your cloud, applications, or different databases, and gets ready to play in the pipeline.
- Playing the Field – Data Transformation: This is where the action happens. Think of data transformation as practicing base running and teamwork. Data engineers step in, clean up the raw data, and transform it into something useful. Like players rounding the bases, the data moves along, getting ready to score insights.
- Passing the Ball – Data Sharing: In baseball, teamwork is epitomized when players pass the ball seamlessly, setting up a perfect play. Similarly, once data is polished, it’s time to ‘pass’ it across. Data sharing ensures that each department or team receives the insights they need.
- The Game Strategy – Data Orchestration: Behind every successful baseball game is a master strategy, with players, positions, and plays orchestrated to precision. In end-to-end data pipelines, data orchestration manages and coordinates the various data processes, ensuring they work in harmony.
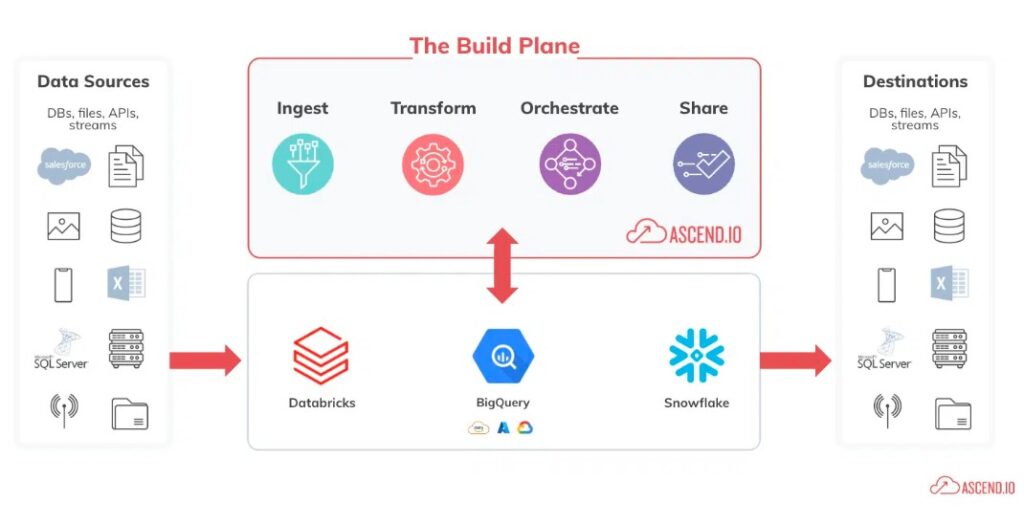
Unified Vision: The streamlined simplicity of an end-to-end data pipeline on a single platform.
Hitting Home Runs with End-to-End Data Pipelines
In today’s data-driven landscape, the methodology employed in managing and processing data can be a pivotal factor for business success. End-to-end data pipelines have emerged as an integral component, and here’s why:
- Unified View and Control: Think of it as having a bird’s-eye view of the entire baseball field, where every player’s position, movement, and strategy are visible. With an end-to-end pipeline, businesses gain a holistic view of their data flow, making it easier to monitor, manage, and make timely adjustments.
- Reduced Complexity: Employing multiple, disparate tools (a.k.a the modern data stack) can introduce unnecessary complications and increase potential points of failure. An integrated pipeline simplifies the landscape, reduces risks, and enhances ease of management.
- Enhanced Data Integrity: Every pass, catch, and hit must be precise to ensure success. Similarly, end-to-end pipelines minimize the chances of data mishandling, ensuring data integrity and reliability.
- Cost and Time Efficiency: Using a multitude of tools can lead to increased operational costs and time expenditures. An integrated pipeline, on the other hand, can significantly cut down on both, offering a more economical and swift approach to data management.
- Improved Agility: In baseball, the ability to quickly change strategy based on the game’s progression can be a winning factor. Similarly, with all data processes under one umbrella, businesses can swiftly adapt to changing data needs and market dynamics.
- Enhanced Collaboration: Just as seamless communication between a pitcher and catcher is vital, having all data processes on a single platform fosters better collaboration between teams. Emphasizing this point, a study from ESG reveals that when it comes to optimizing data usage, the primary investment businesses are making is in technology that promotes better collaboration. It bridges gaps, ensuring everyone is on the same page, and driving towards shared objectives.

A fragmented data approach can lead to missed insights, slower decision-making, and operational inefficiencies. An end-to-end data pipeline aligns every component for optimal performance, ensuring businesses not only stay in the game but also consistently hit those home runs.
No More Mix-and-Match Tools
Imagine the chaos of a baseball team where each player trains with a different coach, follows a unique playbook, and communicates in a different language. The pitcher, catcher, outfielders, and basemen, all crucial to the game, would struggle to coordinate their actions, leading to missed opportunities and glaring errors on the field. Similarly, using disparate tools for each stage of a data pipeline is a recipe for misalignment, inefficiencies, and missed data opportunities.
That’s where we come in. We wrap every single stage in a data pipeline into one neat package. But our value proposition doesn’t stop there. A notable feature of Ascend’s end-to-end data pipelines is our advanced data pipeline automation capabilities. Such automation guarantees that data is processed, updated, and relayed consistently and efficiently. It’s a win-win: while reducing human intervention and potential errors, it paves the way for scalability.
Whether it’s accommodating growing data volumes or evolving business requirements, our automated end-to-end pipelines can accommodate these changes, processing larger datasets efficiently and maintaining their performance.
Harnessing Full Potential of Data
The importance of efficient, reliable, and cohesive data management cannot be understated. End-to-end data pipelines serve as the backbone for organizations aiming to harness the full potential of their data. By consolidating the entire data process within a single framework, businesses can eliminate inefficiencies, reduce errors, and ensure that data flows smoothly from ingestion to final analysis.
The advantages, ranging from enhanced collaboration and consistency to automation and scalability, are compelling. As you navigate the complexities of the data landscape, remember that an end-to-end data pipeline is not just a tool — it’s your MVP, ready to lead your organization to victory in the competitive, data-centric landscape.
Related Reading and Resources
- Harry’s Accelerates Global Marketing Analytics with Intelligent Data Pipelines (Case Study)
- The Post-Modern Data Stack: Boosting Productivity and Value
- 6 Top Data Engineering Predictions for 2023








