




This article is sponsored and originally appeared on Ascend.io.

Let’s be clear: Data pipelines are anything but basic.
Data pipelines are the under-the-hood infrastructure that enables modern organizations to collect, consolidate, and leverage data at scale. They can be incredibly complex networks of code, difficult to untangle and troubleshoot when something goes wrong (and when you’re working with data, something always goes wrong).
But modern organizations are quickly adopting a new approach to scaling pipelines and creating more value from data. In this article, we’ll cover a high-level look at what pipelines are and how they work, including the oft-misunderstood relationship between data pipelines and ETL. Then we’ll dive into the many challenges and how automation can help teams address those challenges to build and maintain better pipelines at scale.
What Is a Data Pipeline?
Simply put, a data pipeline collects data from its original sources and delivers it to new destinations, optimizing, consolidating, and modifying that data along the way. But pipelines are rarely simple. In practice, companies build and operate networks of pipelines that ingest and integrate data from many sources, daisy-chain their output with other pipelines, and deliver it for analysis to many destinations where businesses use it to make decisions.
Ultimately, the core function of a pipeline is to take raw data and turn it into valuable, accessible insights that drive business growth. How exactly that happens can look very different from one organization — and one pipeline — to the next.
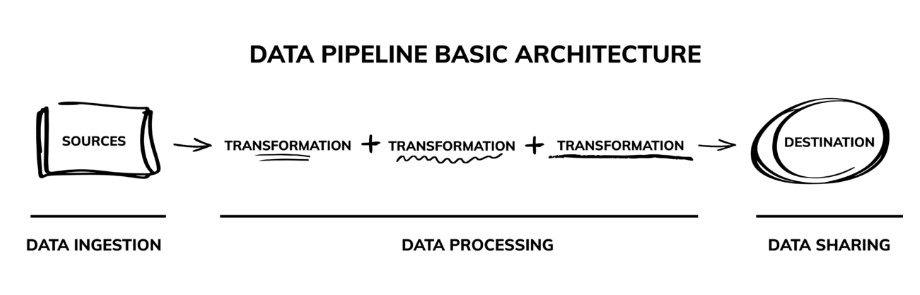
Data Pipeline Components and Processes
Data pipelines can be very straightforward or remarkably complex, but they all share a few basic components:
Ingestion points at the source
A pipeline begins where the data begins: at its sources. Or rather, technically, at the ingestion points: the places where the pipeline connects to the rest of your systems to acquire data.
There are seemingly endless possibilities for data sources, and some examples include:
- Data warehouses
- Relational databases
- Web analytics
- Event trackers
- CRM or marketing platforms
- Social media tools
- IoT device sensors
- CSV files
No matter the sources, data ingestion is the first step of any pipeline, a process that typically happens in batches or as streams.
Transformation and processing
Once data is extracted from the sources, it goes through some processing steps or transformations to make it useful for your business.
These steps can include:
- Augmentation
- Filtering
- Grouping
- Aggregation
- Standardization
- Sorting
- Deduplication
- Validation
- Verification
Basically, these processing steps involve whatever cleansing, merging, and optimization that needs to happen to ready the data for analysis, decision, and action.
Destination and data sharing
Eventually, the final components of a data pipeline are its destinations, which is where the processed data is ultimately made available for analysis and utilization by the business. Often the data lands in storage like a file system or a data warehouse, until the analytics and data science teams are ready to leverage it for insights and decision-making. Pipelines can also be seen to extend beyond such “data sinks” to the end applications that draw from them.
This means pipeline destinations can include:
- Data warehouses
- Data lakes
- Data visualization tools
- Machine learning platforms
- Other applications
- Analytics tools
- API endpoints
The primary goal of the destination is to stage the data for consumption and create business value by helping your company make data-driven decisions with confidence.
Pipeline Architecture Examples
Just like software development in general, pipelines are best built with a “data as a product” mindset. This means that before data engineers start writing code, they should have a clear understanding of how each pipeline will be used, by whom, and for which business goals. By considering functionality, gathering requirements, and understanding how their pipeline will add value to the business, engineers can accelerate development and launch successful pipelines.
Such clarity is important because data pipeline implementations vary widely, depending on the specific insights you want to drive from your data. The most basic design consists of data passing through a number of operations until the result reaches its destination. But many pipelines require more complexity to deliver the desired data product.
For example, let’s say a company’s marketing stack comprises various platforms, including Google Analytics, Hubspot, and LinkedIn Ads. If a marketing analyst wants to understand the effectiveness of an ad, they need a pipeline that consolidates and standardizes data from those disparate sources into destinations where reports can be run and applications can analyze it for the metrics that determine advertising effectiveness.
In such real-world scenarios, data pipelines can become quite complex, with a variety of timing for different data batches, multiple sources of master data, and layering of pipelines for reuse across the business. It all depends on the data you have access to and the requirements of your data products.
Data Pipeline vs ETL
Let’s clear up a quick misconception: data pipelines and ETL are not the same thing.
ETL (which stands for Extract, Transform, and Load) refers to a specific type of data processing. In the ETL process, data is also extracted from a source, transformed, and loaded into a destination. Pipelines, on the other hand, exhibit more complexity, sophistication, and automation.
Some key differences between a data pipeline vs ETL workflow are:
| ETL | Data Pipeline |
| Extract data from a transactional source system into a predetermined target schema | Ingest data from a variety of source systems while preserving their source schemas |
| Manually trigger or schedule jobs to run workflows end-to-end | Continuously process datasets as they are created in the source systems |
| Load data into a data warehouse or data lake | Deliver data products to a variety of applications, tools, and storage systems |
| Workflows run on a single, dedicated (and often proprietary) processing engine | Workflows run on a single, dedicated (and often proprietary) processing engine |
| Workflows are linear fixed sequences of operations | Interdependent processing steps reuse data, requiring complex data orchestration and maintenance of data lineage |
Data Pipelines Challenges
Building and operating robust, end-to-end data pipelines includes efficient sourcing, consolidating, managing, analyzing, and delivering data to create cost-effective business value. Yet as organizations scale their use of data — adding more sources, requiring more complex orchestration, and powering more data products — the traditional method of building and running pipelines is fraught with challenges, such as:
Propagating change
Change is constant in data. And one seemingly small change upstream can trigger a cascade of problems downstream—unless data engineers can manually adjust every step in the pipeline to accommodate the new schema or specifications. When we’re talking about the scale of modern pipelines, that’s a tall order. Propagating change is a huge pain point for data pipelines.
Ensuring data integrity
Too often, when the data flowing through your pipelines isn’t fresh, accurate, or available, business users are the first ones to notice. If your engineering team is lucky, problems are detected early thanks to “wonky numbers” or missing data in a dashboard. If it isn’t, problems remain hidden and lead to bad decisions that cause business performance to suffer.
Data integrity is difficult to achieve because of the time-intensive involvement required by the business. Without it, data engineers are left guessing where to manually implement which data quality checks, leaving many gaps in pipelines where something could possibly go wrong. As it inevitably does.
Optimizing (hidden) costs
Almost every company’s appetite for reliable, accessible, timely, and relevant data outpaces its budget for talent, storage, and compute. To prevent expenses from getting out of hand, optimizing infrastructure and data engineering talent costs is essential, but easier said than done. Over half of these costs can be due to hidden development and runtime burn, inefficiencies, and redundancies.
Fixing frequent outages
In modern organizations, thousands of potential points of error can trigger major business disruptions, burning out understaffed engineering teams and leading to lengthy outages during debug and break-fix cycles of byzantine pipeline code.
Building in a black-box
Pipelines take a lot of work to maintain and grow increasingly complex over time. Usually, only the longest-tenured engineers who originally built the individual pipelines really understand how each one works. This inaccessibility of large code bases makes it difficult to drive efficiency and diagnose problems — especially for new hires.
Scalability
Data pipelines are notoriously difficult to scale, which means data engineering teams are consistently under-resourced. Team members are constantly working to maintain existing pipelines, with little time to build new ones and no bandwidth to take on other analytics and engineering activities that could generate value for the business.
The New Approach to Building Better Data Pipelines at Scale
As we mentioned above, the traditional method of building and managing pipelines brings many challenges. That’s why forward-thinking teams are pursuing a better way: data pipeline automation.
This new approach streamlines day-to-day data engineering tasks and automates change propagation processes,leading to more efficient data pipeline designs, more streamlined data pipeline code, and more accurate and reliable data products. Some advantages of automating pipelines include:
- Intelligent data pipelines that restart from the point of failure, allowing for faster human intervention and quick issue resolution
- Consistent operational metadata generation, enabling engineers to view and monitor pipelines through a single pane of glass
- Automatic retries for failures, deletion, or archiving of orphaned data sets, and cost optimization with detailed breakdowns that help engineers pinpoint problem areas
- Continual data quality checks throughout the pipeline, along with monitoring and alerting for issues, leading to better data integrity and confident business decisions
- Scalability and adaptability to accommodate growing data needs and harness cost advantages across data clouds
Curious how your team can deliver more value from data, at scale? Read our latest whitepaper on data pipeline automation to learn more.







