

This article is sponsored and originally appeared on Ascend.io.

The “modern data stack” is supposed to be like assembling a squad of data software superheroes. You’ve got one solution that’s excellent for ingestion. You connect that to a top-of-the-line data transformation platform. And then, you use best-in-class orchestration, observability, and reverse ETL vendors to monitor and move your data.
The idea is that by combining the power of all of these individual tools, data engineering teams can finally build the kinds of data products your stakeholders need to stay competitive at the speed of modern business. But how did the modern data stack landscape take shape? And is the “modern data stack” truly delivering superhero-grade results?
The promise of assembling a team of specialists and integrating best-in-class software tools is to build efficient, innovative data products. However, the modern data stack landscape continues to evolve, and managing and scaling these tools exacerbates the gaps between them. As demand for data grows, delivering value efficiently and at speed becomes increasingly challenging.
In this article, we’ll:
- Examine the evolution of the data stack
- Discuss the issues that have arisen from the modern data stack complexity
- Explore the next steps in the innovation cycle for data engineering
The Evolution of the Data Stack
Before we dive into the backstory of how we got here, let’s define what a data stack is. A data stack is a collection of technologies, tools, and processes that work together to acquire, process, store, manage, and analyze raw data, transforming it into meaningful insights for an organization.
What we think of as “the modern data stack” today is an evolution of the traditional data stack that can be traced back to physical servers that companies kept on-prem, collecting and storing data that would drive innovation over decades.
The On-Premises Data Stack
Before the cloud became the dominant infrastructure for data storage and processing, the on-premise data stack laid the foundation for how companies managed and utilized their data.
In the on-premise data stack era, companies relied on mainframe hardware stored in server rooms, access to which was limited to a few individuals with the golden keys and the necessary expertise. The data stack consisted of databases and third-party solutions with GUI drag-and-drop interfaces, such as Informatica and SSIS, that essentially wrote the SQL code for you to extract, transform, and load (ETL) data from the transactional databases into data warehouses — while managing their data processing schedules and data mapping needs.
While this on-prem stack of tools worked, it wasn’t ideal.
- Only certain people could use the data
- Buying and maintaining private data centers was incredibly costly
- Processing power was limited, preventing processes from running in parallel
- The paradigm was mostly focused on populating data warehouses
See also: DataOps Trends To Watch in 2023
How the Cloud Impacted Data Engineering
The cloud solved some important disadvantages of on-prem. Companies no longer had to worry about storage and compute costs or limited access to their data. With cloud-based data warehouses, data was all on the cloud, all the time,
However, using the cloud to the fullest extent meant that companies had to go beyond drag-and-drop ETL. The volumes and diversity of data sources expanded, and the types of analytical capabilities to feed with data exploded. The growing complexity drove a proliferation of software and data innovations, which in turn demanded highly trained data engineers to build code-based data pipelines that ensured data quality, consistency, and stability.
Many engineers began learning and using data innovations like Hadoop to standardize and manage distributed datasets in a way that minimized cloud storage and processing costs. And they turned to some of the first out-of-the-box data warehousing tools, like Amazon Redshift, to accelerate their migrations to the cloud and abandon on-prem data warehouses.
With these new tools and resources, companies could:
- Process and view their data in real-time
- Analyze much broader and deeper data sets
- Benefit from far better performance
From a management and purchasing perspective, the cloud made infrastructure much easier. Speed to scale, speed to results, and low CapEx encouraged adoption. But eventually, some of the same problems companies encountered with on-prem data management started to appear.
The Next Stage of Evolution: The Modern Data Stack
Over time, compute costs began to soar as more and more data crowded the cloud data warehouses and data lakes. Because data pipelines were coded from scratch, they started breaking down under the complexity. It became fiendishly difficult to pinpoint the root cause of each issue, let alone fix them without causing knock-on effects throughout the code base.
A market emerged for more advanced tooling that could support sophisticated data processing of huge volumes from the point data entered the data warehouse or data lake to the time of its exit. And just like the cloud burst onto the scene, startups and behemoths raced to identify discrete areas of value across the data pipeline value chain. By zeroing in on specific pain points in specific niches, they could address gaps in data lifecycle management that companies desperately needed to fill. In this initial “big bang” of product development, companies released their own point solutions — often in open-source or free formats to encourage adoption.
Early adopters began to use these tools and helped solidify the key elements that make up a modern data stack. Eventually, a handful of initial “winners” emerged, tools that solved for ingestion, transformation, orchestration, observability, and data delivery (or reverse ETL). Each overcame a different pain point that every data engineer was familiar with.
Impressed by the unique benefits of each product, companies started piecing together their own amalgamations of these specialized tools and integrating them with their existing data infrastructure. Thus, the “modern data stack” landscape was born.
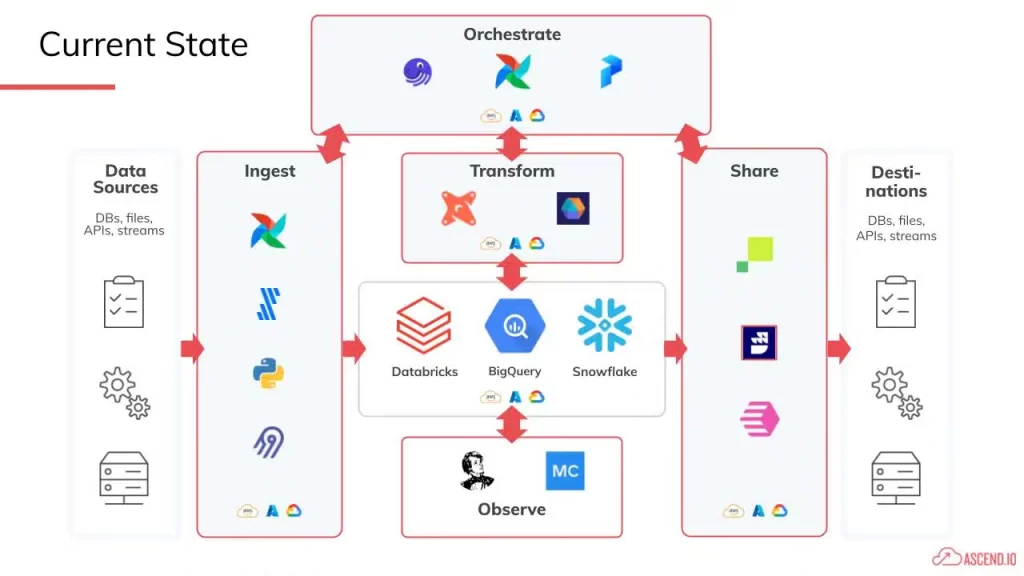
A Brief Review of the Innovation Cycle
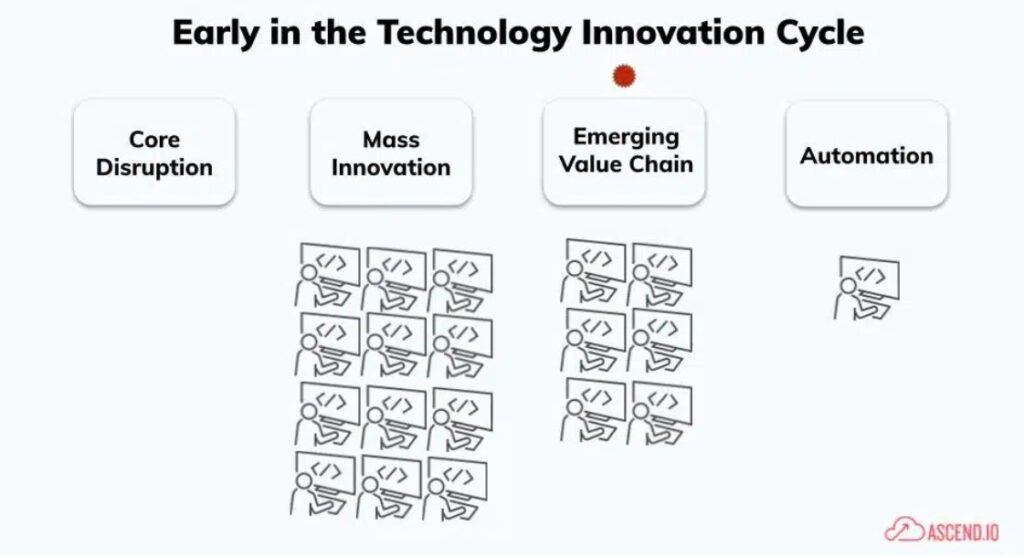
Reading this origin story, it may feel like there was a recurring pattern. We call that pattern “the innovation cycle.” Stage 1 of the innovation cycle is initiated by a revolutionary new technology – in this context, cloud-based data compute such as Redshift, Snowflake, and Spark. This new technology necessitates entirely fresh methods of constructing pipelines to leverage its intrinsic capacity and scalability.
Transitioning into Stage 2, a surge of innovators fills this void, introducing “Big Bang” point solutions into the market. Early adopters are eager to experiment with many of these technologies to help find ones that solve their most pressing challenges.
Stage 3 begins as these early adopters collaborate formally and informally, identifying and documenting best practices and patterns in the form of “reference architectures”. These architectures by design are highlighting the highest areas of value, in our case Ingest, Transformation, Orchestration, Reverse ETL, and Observability, and are eagerly used by companies following close behind the early adopters. They use these reference architectures as both education and guide to accelerate their own data programs.
Stage 4 begins as a critical mass of companies and users begin using this reference architecture in earnest. At even a moderate scale, the loosely coupled nature of this multi-tool approach begins to show significant cracks, negatively impacting the velocity of producing and modifying data products. This pushes the industry into Stage 4, where we see cost and efficiency driven through mass consolidation into a single UI/UX, and a new front of innovation around automation.
So what is the modern data stack, and why is it so popular?
The “modern data stack” is essentially Stage 3 in the innovation cycle for data pipeline technology. It’s a collection of cloud-native tools that data engineers stitch together to build data pipelines.
Companies had the flexibility to choose whatever tools they felt they needed to solve each of their individual pain points, leaning into the idea of building their own “best-of-breed” collection of software. The modern data stack:
- Became the prevailing paradigm: Eventually, everyone in the data space became enamored by these tools, and the modern data stack became the industry standard.
- Is COOL tech: Engineers like working with cool new technologies, and in the early days, the modern data stack landscape presented a wealth of opportunities for developers.
- Has low barrier to entry: Many of these vendors start with open source or free developer tiers in their early days as they don’t need to fully monetize their solution.
- Gets engineers to “Hello World” quickly: Each tool in the stack specializes in a single step or sub-step of the data pipeline. Engineers can optimize the user experience (UX) to make onboarding and daily use easy and results-oriented.
Why is the modern data stack so challenging?
But like every stage of the data management and processing evolution, the weaknesses of the modern data stack have come to outweigh its benefits. Trying to manage and scale a broad stack of technologies with a small number of people in the face of growing demand and data volumes is a near-impossible feat.
The modern data stack causes myriad issues, including:
- Increased headcount: The knowledge required to operate each best-of-breed tool requires engineers to hyper-focus their skill sets. As a result, only certain engineers can work on certain tasks, creating complicated workflows and bottlenecks to speed, quality, and delivery.
- Lengthy onboarding: New joiners aren’t valuable until they gain administration experience. And learning the ins and outs of each tool on top of understanding the structure and meaning of the data being processed becomes a lengthy and error-prone undertaking.
- Time-intensive integrations: Attempting to connect and close the seams between multiple data pipeline tools takes substantial time and effort. Besides one-time implementations, engineers must keep up with changes to APIs, handle special scenarios, and monitor and resolve connectivity issues.
- Complex full-stack administration and security: Many enterprises have thousands of interconnected pipelines pulling data from diverse data sources and spreading processing across multiple clouds, each one with its distinct functionality and security models. One misstep in one pipeline or update in a single cloud service can impact hundreds more.
- Growing expense: Since every vendor in the stack wants to maximize its own revenue, companies often pay far more for each tool than the value it confers.
Most importantly, the modern data stack can’t scale. Adding more and more tools to the mix hinders velocity; the simplest changes take weeks or months to evaluate, test, and ensure expected outcomes, slowing the entire company down.
The modern data stack has hit a tipping point
Instead of focusing their time on delivering the data products their stakeholders want and need, developers are increasingly scrambling to keep up with technology changes and limitations, and trying to keep the modern data stack running.
As Venture Beat describes, “They have to assemble, integrate and manage all their disparate tools at the same time, which means paying not only for the technology in use but for engineering time and opportunity cost. This directly impacts ROI.”
While point solutions do solve individual niche problems, in aggregate they actually contribute to a monolithic and static architecture that decelerates progress and stalls innovation.
- Data engineering processes are deeply ingrained in the underlying technical implementation of niche data pipeline tools, making it near impossible to streamline workflows and increasing the potential for costly mistakes.
- Engineers don’t know how much infrastructure and licenses cost to run each data pipeline, limiting their ability to diagnose inefficiencies and preventing their contributions from aligning with the company’s overall goals.
- The modern data stack has disjointed the collaboration between data analysts, data scientists, and product owners. Since they don’t work on the same platform and don’t see each other’s processes, handoffs are weak, communication is poor, and siloes form. Decision tools and data applications are fed with inaccurate or stale data, and company performance suffers.
As thought leader Lauren Balik puts it, the modern data stack is “an increasingly complex layer of human middleware, making tables and tables and tables on a centralized cloud data warehouse. Engineers chase down KPIs for the business but are dependent on the application owners who are not incentivized to care about the quality of the data they produce.”
Right now, we’re solidly in Stage 3 of the innovation cycle, and the modern data stack landscape is ready for the next wave of innovation: end-to-end automation.
Change Is Coming to the Modern Data Stack
While the modern data stack has come a long way from the monolithic on-premises data centers of years past, it’s not the end-all-be-all (and what better than Reddit for a reality check?) The truth is that the more puzzle pieces there are, the harder it is to put the puzzle together.
The modern data stack landscape comes with an integration tax, perpetuates the need for expensive, highly specialized resources, and complicates change management. And companies have hit a breaking point — instead of realizing the full ROI of their data, they’re spending their time and energy cleaning up their data stack mess.
With fully automated and end-to-end solutions, data engineers are relieved of the need for complex integrations and the manual work that comes with data pipeline maintenance. They can get back time to develop closer relationships with business stakeholders and build the data products that really matter.
Paul Lacey is Head of Product Marketing at Ascend.io.


